Nano vLLM 解读(5):解析 ModelRunner
在 Nano vLLM 中,LLMEngine 是系统的外层入口,它负责接收请求、维护 tokenizer、调用 scheduler,并推动整个推理流程一步一步向前走。回顾我们在 Nano vLLM 解读(1):LLMEngine 架构与推理流程解析 里介绍的整个推理 pipeline 如下图所示:
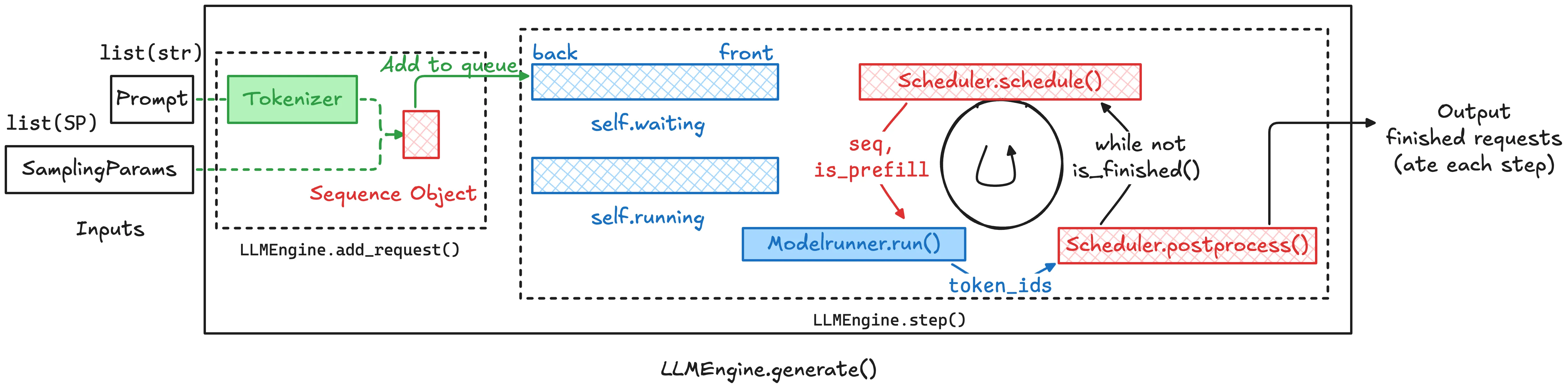
ModelRunner 则是更靠近 GPU 的执行层。它不负责决定哪些请求应该被调度,也不负责管理请求生命周期;它真正负责的是:当 Scheduler 已经选出一批要执行的 Sequence 之后,如何把这些动态、不规则的请求组织成 GPU 可以高效执行的张量形式,然后调用模型完成一次前向计算,最后通过 sampler 得到下一个 token。
ModelRunner 初始化:构建 GPU 上的执行环境
ModelRunner 由 LLMEngine 创建。初始化时,它首先根据当前 rank 初始化分布式环境,并绑定对应的 CUDA 设备。随后,代码会临时把 PyTorch 的默认 dtype 设置为模型配置中的 dtype,并把默认 device 设置为 CUDA。这样后续构造模型时,模型参数会直接创建在 GPU 上,而不是先创建在 CPU 再移动过去。
dist.init_process_group("nccl", "tcp://localhost:2333", world_size=self.world_size, rank=rank)
torch.cuda.set_device(rank)
torch.set_default_dtype(hf_config.torch_dtype)
torch.set_default_device("cuda")
self.model = Qwen3ForCausalLM(hf_config)
load_model(self.model, config.model)这里需要注意一点:Nano vLLM 中的 world_size 来自 tensor_parallel_size。它启动了多个 ModelRunner 进程,每个 rank 绑定一张 GPU,并通过分布式通信环境协同工作。
模型加载完成之后,ModelRunner 会创建 sampler,并进行 warmup。warmup_model() 通过构造接近上限的输入,触发一次较大的前向计算(具体执行过程请见后文 ModelRunner.run:从 Sequence 到一次模型前向),从而让 PyTorch 记录模型执行时的峰值显存。后面分配 KV Cache 时,代码会根据当前显存、峰值显存以及目标显存利用率,估算还能留给 KV Cache 多少空间。
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
self.run(seqs, True)
torch.cuda.empty_cache()这一步很重要,因为推理服务中 KV Cache 往往是显存的大头。如果 KV Cache 分配得太少,可同时服务的 token 数量就少;如果分配得太多,又可能挤占模型执行需要的临时显存,导致运行时 OOM。因此 Nano vLLM 采用的策略是:先让模型跑一次,估计模型执行本身需要多少显存,然后把剩余显存尽可能分给 KV Cache。
KV Cache 的分配发生在 allocate_kv_cache() 中。代码首先读取 GPU 的总显存和空闲显存,然后根据每个 KV block 的大小计算可以分配多少个 block。一个 block 的大小由层数、block size、KV head 数、head dim 和 dtype 大小共同决定。
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * head_dim * hf_config.torch_dtype.itemsize
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes这里的 2 对应 key cache 和 value cache。也就是说,每个 token 在每一层都需要保存一份 key 和一份 value。num_hidden_layers 表示所有 Transformer layer 都要有自己的 KV Cache;self.block_size 表示每个 block 能容纳多少个 token;num_kv_heads 和 head_dim 则决定了每个 token 的 KV 向量大小。
随后,Nano vLLM 一次性创建一个巨大的 KV Cache tensor:
self.kv_cache = torch.empty(
2,
hf_config.num_hidden_layers,
config.num_kvcache_blocks,
self.block_size,
num_kv_heads,
head_dim
)这个 tensor 的维度可以理解为:
[key/value, layer_id, block_id, token_offset_in_block, kv_head, head_dim]之后,代码会遍历模型中的每个 attention module,把对应层的 k_cache 和 v_cache 指向这块大 tensor 中对应 layer 的切片。这样一来,attention 层在执行时并不需要自己管理 KV Cache 的显存,它只需要根据传入的 slot_mapping 和 block_tables,把新生成的 KV 写入正确位置,并在 attention 计算时读取历史 KV。
多卡场景:rank 0 作为控制者,其余 rank 被动执行
当 world_size > 1 时,Nano vLLM 会启动多个 ModelRunner 实例。这里的一个关键设计是:rank == 0 的 ModelRunner 是主控实例,而其他 rank 的 ModelRunner 会进入一个 loop() 循环,等待 rank 0 通过共享内存发送指令。
rank 0 会创建一块名为 "nanovllm" 的共享内存:
self.shm = SharedMemory(name="nanovllm", create=True, size=2**20)其他 rank 则打开同名共享内存:
self.shm = SharedMemory(name="nanovllm")
self.loop()worker rank 进入 loop() 后,会不断调用 read_shm()。这个函数首先等待 event 被设置,然后从共享内存前 4 个字节读出数据长度,再反序列化后面的 pickle 数据,得到要执行的方法名和参数。
self.event.wait()
n = int.from_bytes(self.shm.buf[0:4], "little")
method_name, *args = pickle.loads(self.shm.buf[4:n+4])
self.event.clear()这个机制本质上是一个非常轻量的 RPC。rank 0 并不是通过共享内存传递大规模 tensor,而是传递控制命令:例如调用哪个方法、传入哪些 Python 参数。rank 0 调用 call("run", seqs, is_prefill) 时,会先把这个方法名和参数写进共享内存,然后用 event 唤醒其他 rank。其他 rank 被唤醒之后,读取共享内存里的命令,然后执行同名方法。
def call(self, method_name, *args):
if self.world_size > 1 and self.rank == 0:
self.write_shm(method_name, *args)
method = getattr(self, method_name, None)
return method(*args)所以在多卡场景中,rank 0 的角色比较特殊。它既负责通知其他 rank 执行同一个方法,也会在本地执行这个方法。其他 rank 则不主动调度请求,只是等待 rank 0 发来的命令。这个结构非常简洁,但也意味着它更像是教学版或最小实现版,不是生产级推理引擎中复杂的 worker 管理系统。
ModelRunner.run:从 Sequence 到一次模型前向
当 LLMEngine.step() 中的 Scheduler.schedule() 已经选出一批请求后,真正的执行会进入 ModelRunner.run()。这个函数很短,但它串起了整个模型推理路径。
def run(self, seqs: list[Sequence], is_prefill: bool) -> list[int]:
input_ids, positions = self.prepare_prefill(seqs) if is_prefill else self.prepare_decode(seqs)
temperatures = self.prepare_sample(seqs) if self.rank == 0 else None
logits = self.run_model(input_ids, positions, is_prefill)
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None
reset_context()
return token_ids这段代码可以分成四个阶段。第一步是准备模型输入,包括 input_ids 和 positions,同时还会通过 set_context() 准备 attention kernel 所需要的上下文信息。第二步是准备采样参数,例如每个请求对应的 temperature。第三步是真正执行模型前向,得到 logits。第四步是在 rank 0 上进行采样,得到最终生成的 token id。
这里最关键的不是 run_model(),而是 prepare_prefill() 和 prepare_decode()。因为模型前向本身只是标准 Transformer 计算,真正困难的是:一个 batch 里面的请求长度不同、KV Cache 位置不同、prefix cache 命中情况不同,如何把它们组织成 FlashAttention / PagedAttention 可以理解的格式。
FlashAttention Kernel 函参准备:prepare_prefill 和 prepare_decode
在 Nano vLLM 这样的实现中,模型 forward 表面上只传入了:
self.model(input_ids, positions)但真正执行 attention 时,kernel 需要的信息远不止这些。可以把它们分成三类。
第一类是当前 token 的基本信息,也就是 input_ids 和 positions。input_ids 用于 embedding lookup,positions 用于位置编码,尤其是 RoPE。如果 position 错了,即使 token 内容正确,attention 的相对位置信息也会错。
第二类是变长 batch 的边界信息。prefill 中最重要的是 cu_seqlens_q、cu_seqlens_k、max_seqlen_q 和 max_seqlen_k。cu_seqlens_q 告诉 kernel flatten 后的 query tensor 中,每个请求从哪里开始、到哪里结束;cu_seqlens_k 告诉 kernel key/value 的边界;max_seqlen_q 和 max_seqlen_k 则用于 kernel 内部确定最大处理长度,便于选择 tile 或分配临时计算结构。
第三类是 KV Cache 的寻址信息,也就是 slot_mapping、block_tables 和 context_lens。slot_mapping 负责写入:当前 token 产生的新 KV 应该写入哪个物理 cache slot。block_tables 负责读取:某个请求的历史 KV 分布在哪些物理 block 里。context_lens 主要用于 decode,表示每个请求当前有效上下文长度,防止 kernel 读到 padding 或尚未写入的 cache 位置。
因此,FlashAttention / PagedAttention 要求上层系统把变长请求、prefix cache、paged KV cache 这些复杂状态全部编码成 kernel 能理解的参数。ModelRunner.prepare_prefill() 和 ModelRunner.prepare_decode() 正是在做这件事。
prepare_prefill:把变长请求打包成 FlashAttention 输入
prefill 阶段处理的是 prompt,也就是一次性输入多个 token。不同请求的 prompt 长度可能不同,有些请求还可能已经命中了 prefix cache,因此只需要计算未缓存的后缀 token。这时 prepare_prefill() 要做的事情,就是把这些不规则的序列拼接成连续 tensor。
它首先构造 input_ids。这里不是简单把每个请求完整 prompt 都放进去,而是从 seq.num_cached_tokens 开始,只取还没有被缓存的 token。
input_ids.extend(seq[seq.num_cached_tokens:])
positions.extend(list(range(seq.num_cached_tokens, seqlen)))这说明如果一个请求前面若干 token 已经命中 prefix cache,那么这部分 token 不需要重新进入模型计算。模型只需要计算从 num_cached_tokens 到当前序列末尾的新增部分。对应的 positions 也要从真实位置开始,而不是从 0 开始,否则 RoPE 这类位置编码会错位。
接下来,代码构造 cu_seqlens_q 和 cu_seqlens_k。这是 FlashAttention 处理变长序列时非常重要的参数。因为变长 batch 不能简单表示成 [batch_size, max_seq_len] 而不付出 padding 成本,所以更高效的做法是把所有 token flatten 成一个连续的一维 token 序列,然后用 cumulative sequence lengths 表示每个请求的边界。
cu_seqlens_q 表示 query 序列的边界,cu_seqlens_k 表示 key/value 序列的边界。对于普通 prefill,如果没有 prefix cache,那么每个请求的 query 长度和 key 长度相同。但如果命中了 prefix cache,query 只包含新增 token,而 key/value 则包含历史缓存 token 加上新增 token。因此会出现:
cu_seqlens_k[-1] > cu_seqlens_q[-1]这正是代码判断是否需要 block_tables 的条件。
FlashAttention kernel 在 prefill 阶段通常需要这些信息:input_ids 用来查 embedding,positions 用来计算位置编码,cu_seqlens_q 用来知道每个请求的 query 范围,cu_seqlens_k 用来知道每个请求可见的 key/value 范围,max_seqlen_q 和 max_seqlen_k 用来决定 kernel 内部 tile 的最大边界,slot_mapping 用来把当前新 token 生成的 KV 写入 KV Cache 的物理位置。如果存在 prefix cache,还需要 block_tables 来告诉 attention kernel:某个请求的历史 KV 分布在哪些物理 block 中。
其中 slot_mapping 是理解 KV Cache 的关键。它回答的问题不是“这个 token 在逻辑序列中的位置是多少”,而是“这个 token 生成出来的 KV 应该写到 KV Cache 的哪个物理槽位”。代码中对每个 sequence 遍历它尚未缓存的 block,并把 block id 转换成线性的物理 slot。
start = seq.block_table[i] * self.block_size
end = start + self.block_size
slot_mapping.extend(list(range(start, end)))如果是最后一个 block,它可能没有填满,所以结束位置要用 last_block_num_tokens 修正。这个映射非常重要,因为 KV Cache 是一个预分配的大池子,逻辑上连续的 token 并不一定物理上连续存放。slot_mapping 就是从逻辑 token 到物理 cache slot 的桥梁。
最后,prepare_prefill() 会把这些 CPU 上构造好的 Python list 转成 tensor,并通过 pinned memory + non-blocking copy 异步搬到 GPU 上。
torch.tensor(..., pin_memory=True).cuda(non_blocking=True)然后它调用:
set_context(True, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, None, block_tables)这个 set_context() 可以理解为给后面的 attention 层设置一次全局执行上下文。模型的 forward 函数表面上只接收 input_ids 和 positions,但 attention 层内部会通过 get_context() 取出这些参数,从而知道当前是在 prefill 还是 decode,应该如何读写 KV Cache,以及如何调用对应的 attention kernel。最重要的是通过设置 context 参数,可以把动态输入从函数签名中剥离出来,让 CUDA Graph 能复用;在运行时去根据具体输入读取。
prepare_decode:每个请求只输入一个新 token
decode 阶段和 prefill 阶段的结构完全不同。decode 时,每个请求通常只新生成一个 token,因此 query 长度是 1;但每个请求已经积累了很长的历史 KV,因此 key/value 长度可能很长。这也是为什么 decode 通常更容易受到 KV Cache 读取带宽限制。
prepare_decode() 中,每个 sequence 只取最后一个 token 作为输入:
input_ids.append(seq.last_token)
positions.append(len(seq) - 1)
context_lens.append(len(seq))这里的 positions 是当前 token 在完整序列中的位置。context_lens 则告诉 attention kernel:对于这个请求,当前一共有多少 token 可以被 attention 看到。decode kernel 需要根据 context_lens 避免读到无效的 KV 区域。
decode 中同样需要 slot_mapping。因为当前 token 前向计算后会生成新的 key/value,这个新的 KV 需要写入该请求当前最后一个 block 的对应位置。
slot_mapping.append(seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1)这里的逻辑是:seq.block_table[-1] 找到最后一个逻辑 block 对应的物理 block id,乘以 block_size 得到这个 block 在线性 KV Cache 中的起点,再加上 last_block_num_tokens - 1 得到当前 token 应该写入的位置。
decode 阶段一定需要 block_tables。因为虽然 query 只有一个 token,但它需要 attend 到整个历史上下文,而历史 KV 是按 block 存在 KV Cache 中的。block_tables 就是告诉 kernel:对于第 i 个请求,它的第 j 个逻辑 block 对应 KV Cache 中的哪个物理 block。
最后,decode 阶段通过:
set_context(False, slot_mapping=slot_mapping, context_lens=context_lens, block_tables=block_tables)设置 attention 上下文。和 prefill 不同,decode 不需要 cu_seqlens_q 和 cu_seqlens_k,因为每个请求只有一个 query token;它更关心的是 context_lens 和 block_tables,也就是如何从 KV Cache 中找到完整历史上下文。
run_model:普通前向和 CUDA Graph replay
准备完输入后,ModelRunner 会进入 run_model()。如果当前是 prefill,或者强制 eager,或者输入 token 数太大,那么代码直接走普通 eager 前向:
return self.model.compute_logits(self.model(input_ids, positions))如果是 decode,并且 batch size 不大,则可以走 CUDA Graph。decode 阶段每一步的计算模式非常固定:每个请求一个 token,主要区别只是 batch size、positions、slot_mapping、context_lens 和 block_tables 的内容不同。这类计算非常适合 CUDA Graph,因为 CUDA Graph 可以把一系列 kernel launch 预先捕获下来,后续只需要更新输入 buffer,然后 replay graph,减少 Python 调度和 kernel launch 开销。
代码中会根据当前 batch size 选择一个不小于它的 graph:
graph = self.graphs[next(x for x in self.graph_bs if x >= bs)]然后把真实输入复制到预分配的 graph buffer 中:
graph_vars["input_ids"][:bs] = input_ids
graph_vars["positions"][:bs] = positions
graph_vars["slot_mapping"][:bs] = context.slot_mapping
graph_vars["context_lens"][:bs] = context.context_lens
graph_vars["block_tables"][:bs, :context.block_tables.size(1)] = context.block_tables随后调用:
graph.replay()这里的关键思想是:CUDA Graph 捕获的是“计算图结构”,而不是某一次请求的具体值。因此 replay 前只需要把当前 step 的数据写入固定 buffer,graph replay 时就会使用这些新数据执行同样的 kernel 序列。对于 decode 这种小 batch、小 token、重复执行的场景,这可以显著降低调度开销。
不过,prefill 通常不适合直接用 CUDA Graph,因为 prefill 的 token 数、序列长度、prefix cache 命中情况变化很大,shape 太动态,graph 捕获和复用都比较困难。
Sampler:只有 rank 0 产生最终 token
模型前向结束后会得到 logits。真正的采样只在 rank 0 上进行:
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None这是因为最终的生成结果只需要由主控 rank 返回给上层 LLMEngine。其他 rank 即使参与了模型计算,也不需要各自返回 token id。prepare_sample() 中构造的 temperature 也是只在 rank 0 使用。
采样完成之后,run() 会调用:
reset_context()这一步不能省略。因为 set_context() 设置的是当前这一次 forward 所需的 attention 上下文。如果不清理,下一次 prefill 或 decode 可能会读到上一次残留的 slot_mapping、block_tables 或 context_lens,从而造成错误的 KV Cache 读写。可以把 set_context() 和 reset_context() 理解为 attention kernel 的一次作用域管理:进入模型前设置上下文,模型执行结束后清空上下文。