MoE 模型基础
基本介绍
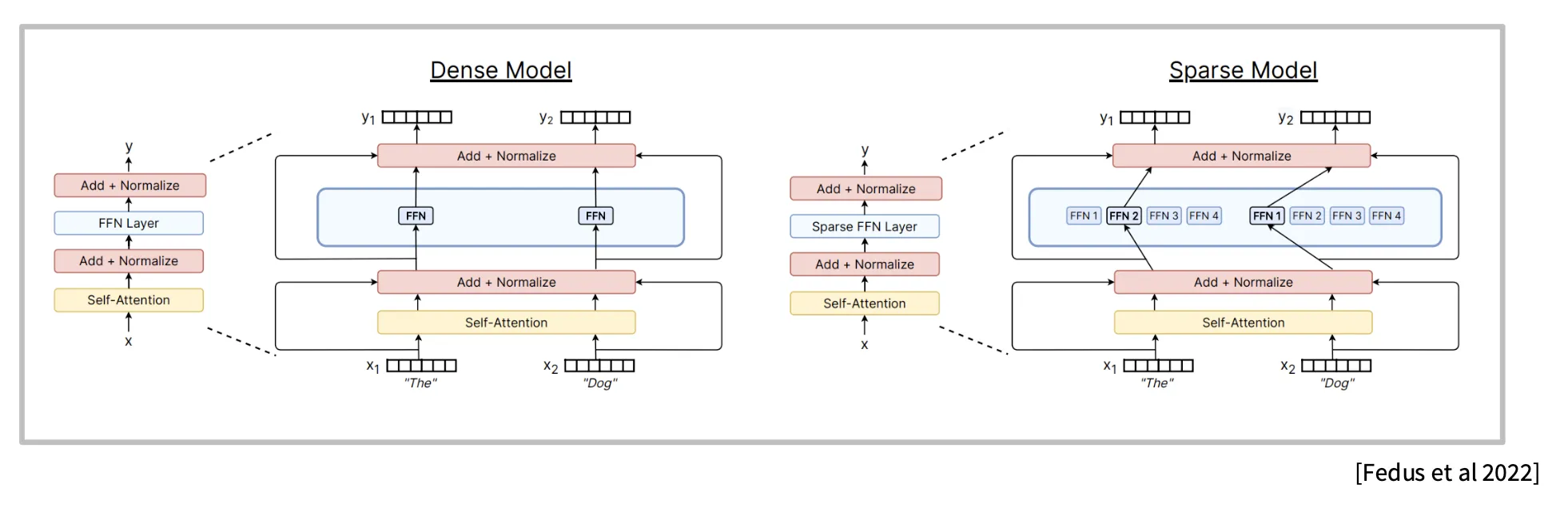
Mixture of Experts (MoE) 模型:
- 将传统 FFN 替代为路由器 + 很多稀疏的 FFN,也叫 Experts
- 每次推理过程中选择 Experts 的子集
优势:
- 在相同的 FLOPS 下模型有更多的参数,因此模型性能表现更好、训练更快(实验证明)
- 多一种并行方式:EP
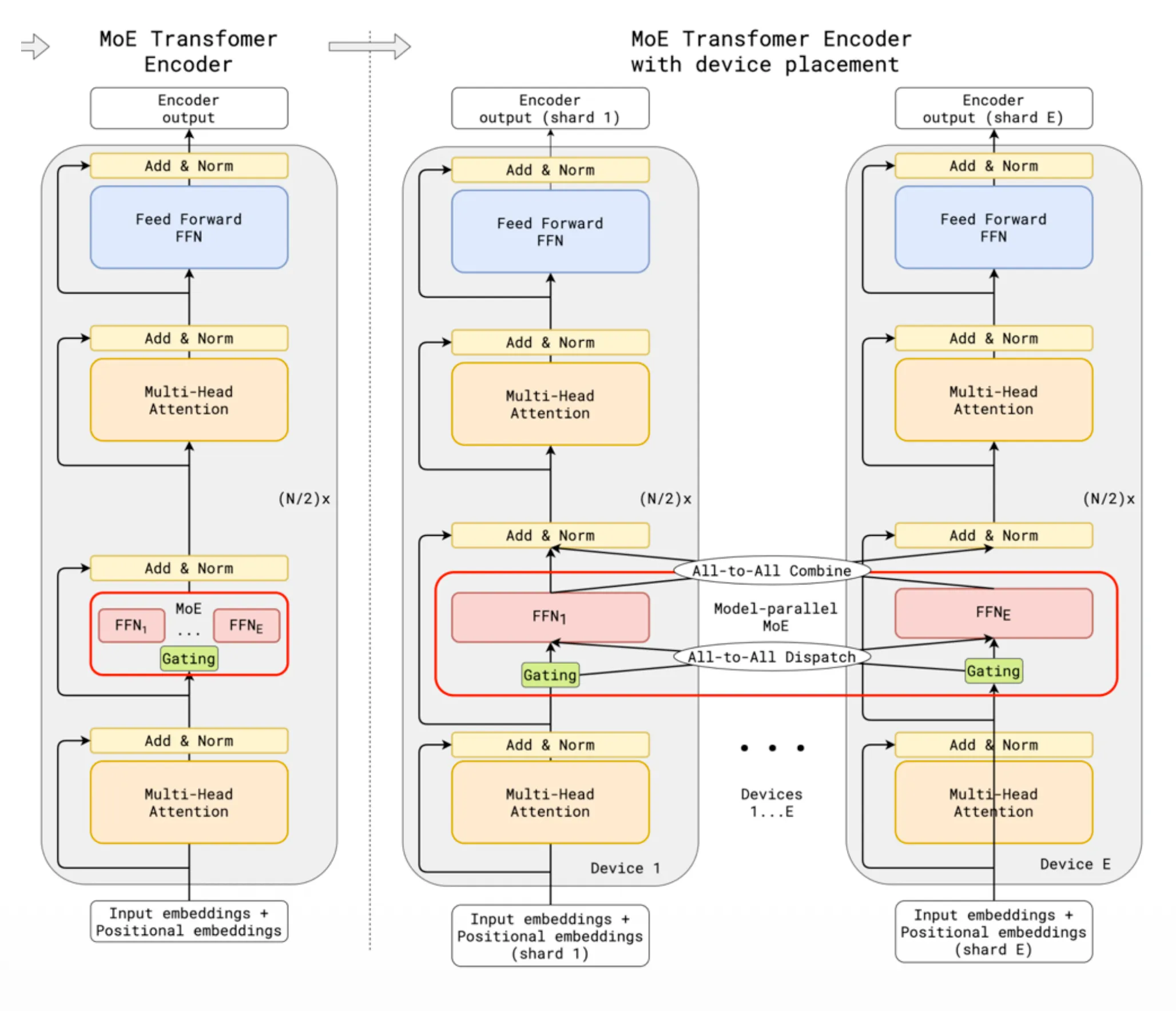
为什么 MoE 不是很流行:
- MoE 在多 node 下优势更明显
- Routing 很难训练(不可微),优化问题
有些人把 Attention 也 MoE 了
What varies
路由函数
路由方式
如何 match token to experts?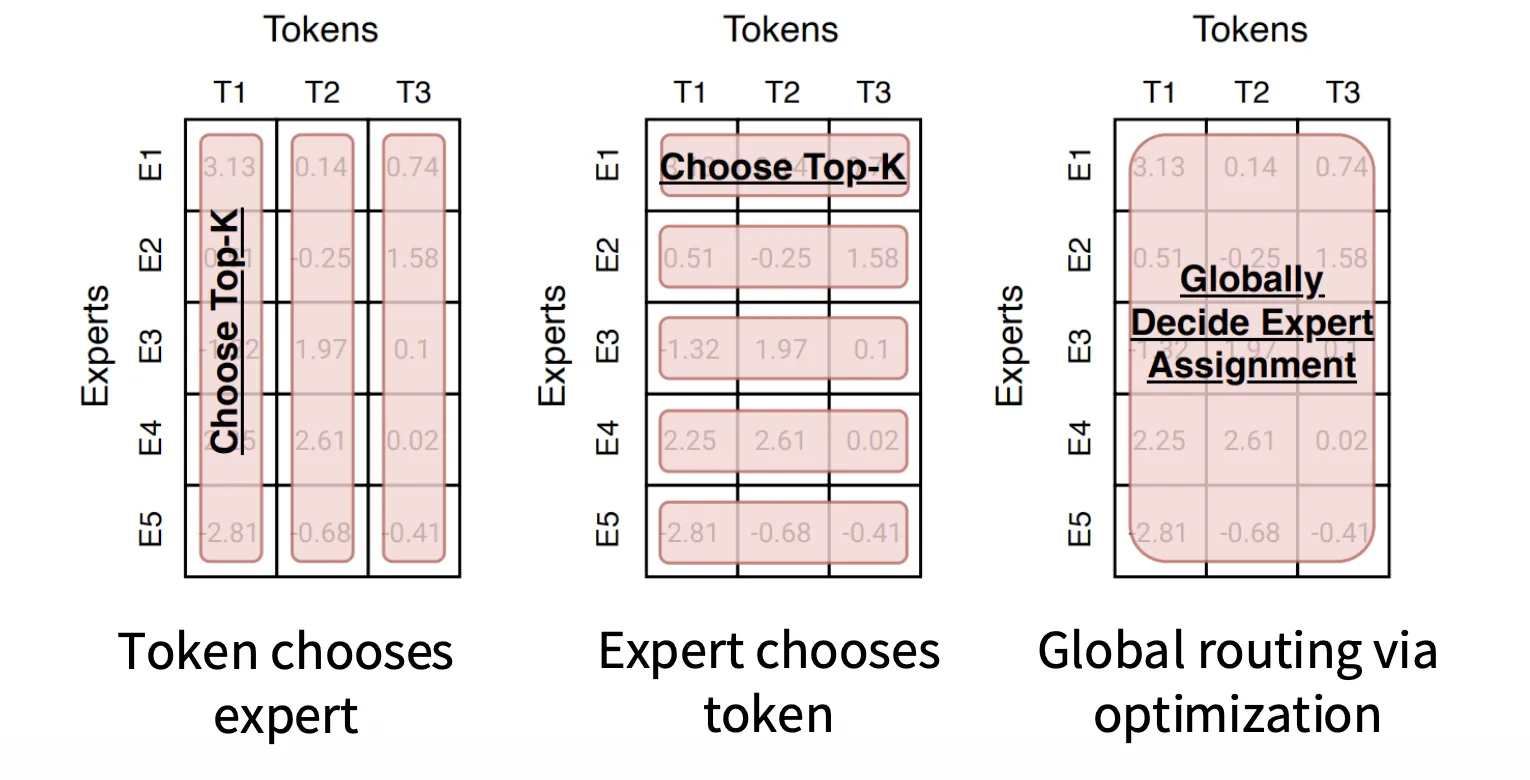
现在基本上所有模型都是 Token chooses expert,尽管第二种显得更加平衡,第一种目前而言性能是最强的
在 Token chooses expert 类下,有以下几种选择方式:
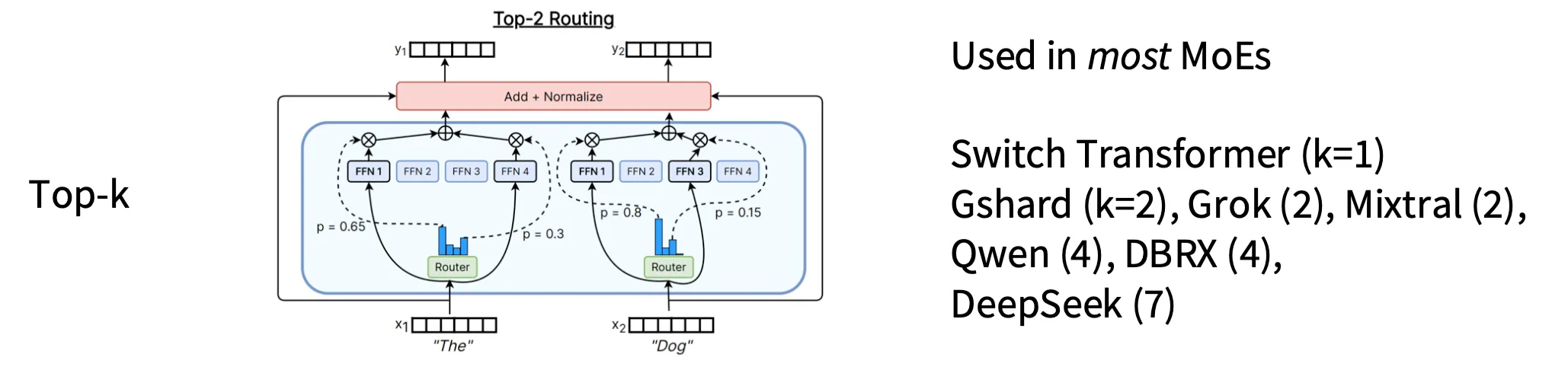
- Top-k:最常用
- Hashing:作为 Baseline. 实验证明单纯哈希也能获得性能收益
- RL:计算开销太大,性能不稳定
- 问题建模 Linear Assignment:开销很大
Top-k routing
假设在第 层,输入为 表示在 batch 中的第 个 Token
其中通过 logistic regressor 得到权重:
其中:
- Top-K 保证只有一部分专家会被激活
- 是 Router 对应 Expert 的特征向量或者叫 embedding
- 使得非零 加起来尽量为 1
- 是个 Residual stream
Shared Expert
更多更小的 Experts + 几个(或者一个)共享 Expert 对于所有 Token 都会被激活
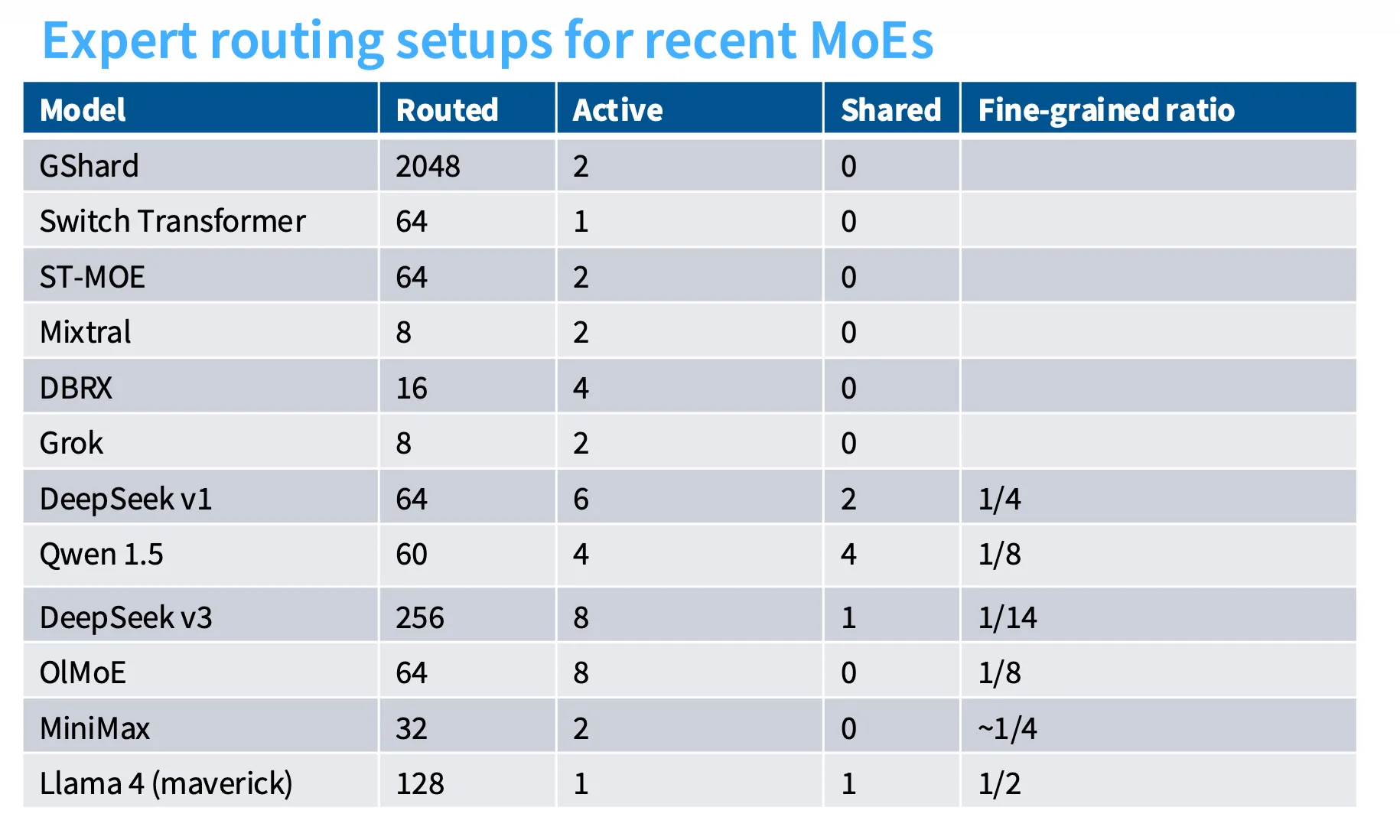
Expert sizes
在 Expert 数量增多的同时,与 Dense 模型的 FFN 相比,MoE Experts 大小按一定比例进行缩小
如何训练
- 训练的时候,不会把所有 Expert 都打开(不然训练代价要翻好几倍)
- Sparse gating decision 显然不可微
RL
不是特别有效,比 Hashing 好一点
Stochastic 近似
通过加噪声
使得所有 expert 是否进入 top-k 变成一个有概率事件,随后再
效果同样一般
Heuristic ‘(load) balancing losses’
目的是为了平衡各个 Expert 所路由的 Token 数量。(为什么平衡?不然模型很可能会把所有的 Token 路由到同样的一部分 Expert 然后其他 Expert 就像 “Dead” 了一样)
[Switch Transformer]: 对于每一层,定义 auxiliary loss 负载均衡损失为:
其中 是 Expert 个数, 是一个 batch Token 的数量。对于每个 Expert ,定义:
- 实际分配的 Token 个数为
- 理论上应该分配的 Token 数量:
不仅如此,还有 Per-expert balancing 和 Per-device balancing
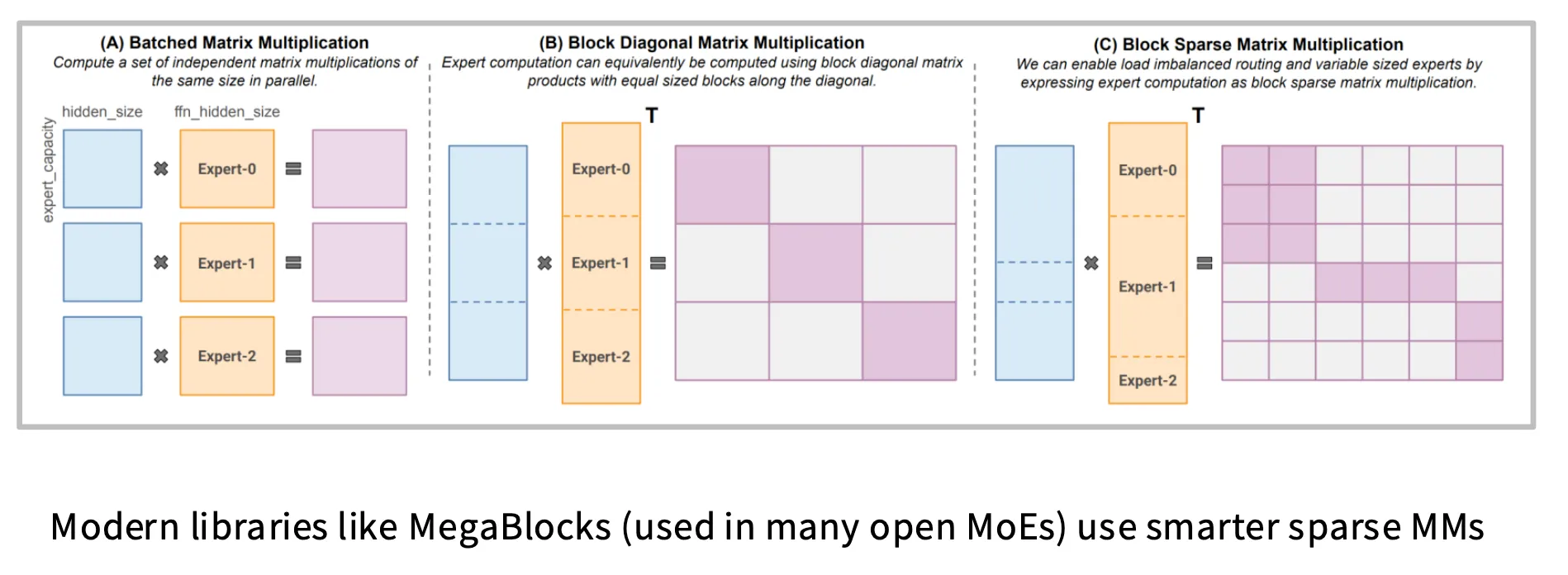
Expert 计算优化:Block-sparse GEMM
MoE 问题
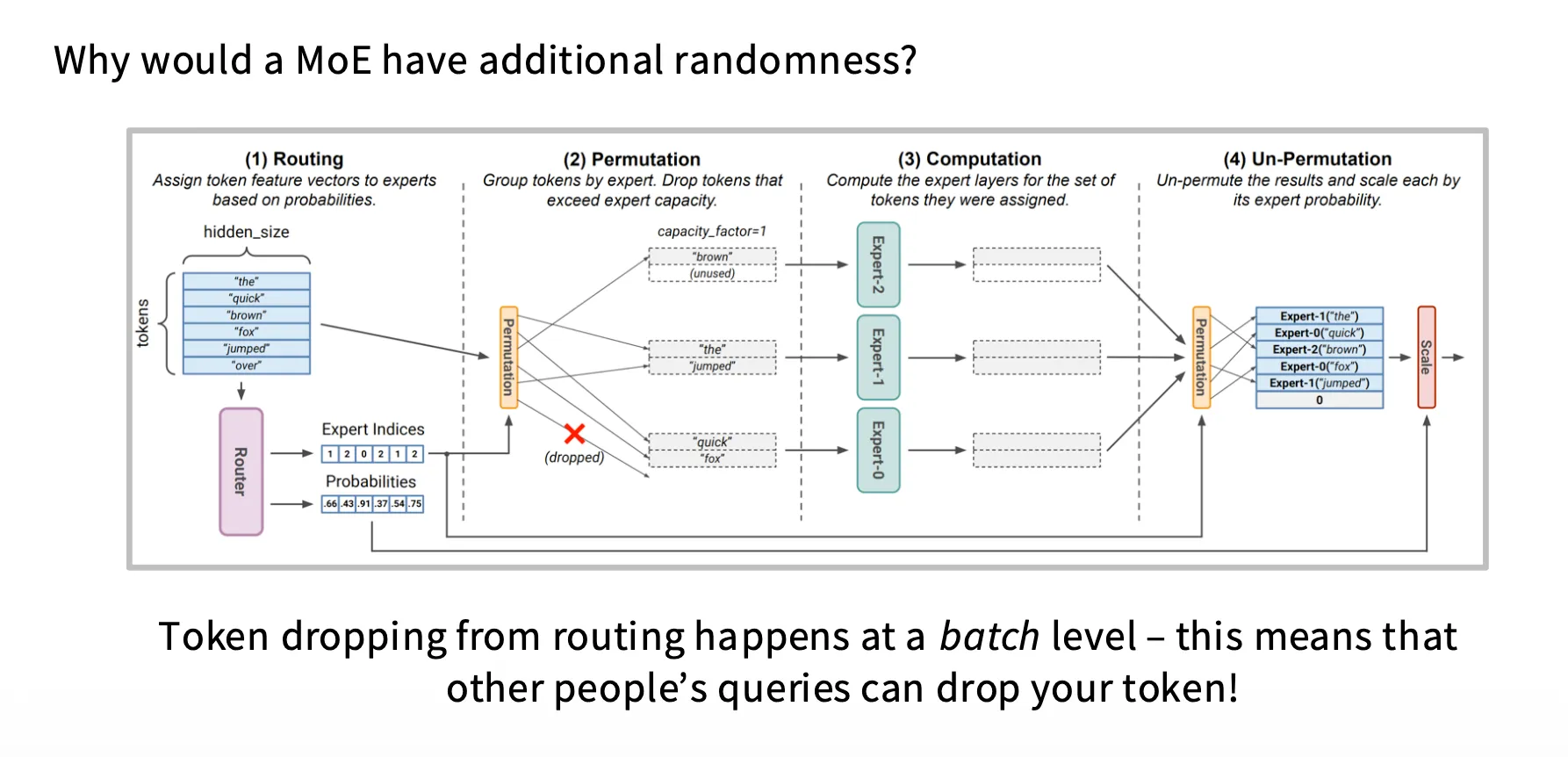
Stochasticity
在推理过程中,会有个 capacity factor,避免在某批次里面 Expert 无法 load 所有在一个 batch 中的 Token。当某个 batch 使得特定 expert 的 load factor 超过了阀值时,一部分 expert 会直接被丢弃并被原模原样地输出(因为residual)。
由于这和推理过程所属的 batch 动态相关,因此即使随机参数一样,相同的输入也有可能会产生不同的结果。
Stability
为了减少 Softmax 带来的不稳定,训练的时候用 Float 32,以及 auxiliary z-loss.
不适合微调,容易过拟合
MoE 训练技巧:Upcycling
从一个已经训练好的 Dense 模型开始,将 FFN 复制多份成为 Experts,从零创建一个 Router,在原来的 Dense 模型基础上继续训练
DeepSeek MoE v1-v2-v3
v2: 结构保持一致,加了一些 Expert;为了减少通信开销,多了 Top-M device routing:首先选 Device 再选 Expert.
在训练过程中额外考虑了 Token 的 output communication cost
v3: Sigmoid+Softmax topK + topM. 以及 Aux-loss-free 减少依赖 balancing loss + seq-wise aux 以避免在推理时,极端的输入导致 Expert 过载,相比于 Batch level 来说更细粒度的平衡
参考资料
CS336