Nano vLLM 解读(3):解析 Scheduler
本文从 Nano-vLLM 入手,解读如何实现一个轻量级的大模型请求调度器。
请求调度:Scheduler 类
上层调度 API:LLM Engine 的调用方式
本小节对应 Nano vLLM 的
Engine.generate()API,点击链接跳转。
在具体看 Scheduler 的实现细节之前,我们先研究一下 LLM Engine 是如何调用 Scheduler 的 API 的。在 Nano vLLM 解读(1):LLMEngine 架构与推理流程解析 中我们分析了 LLM Engine 的结构: 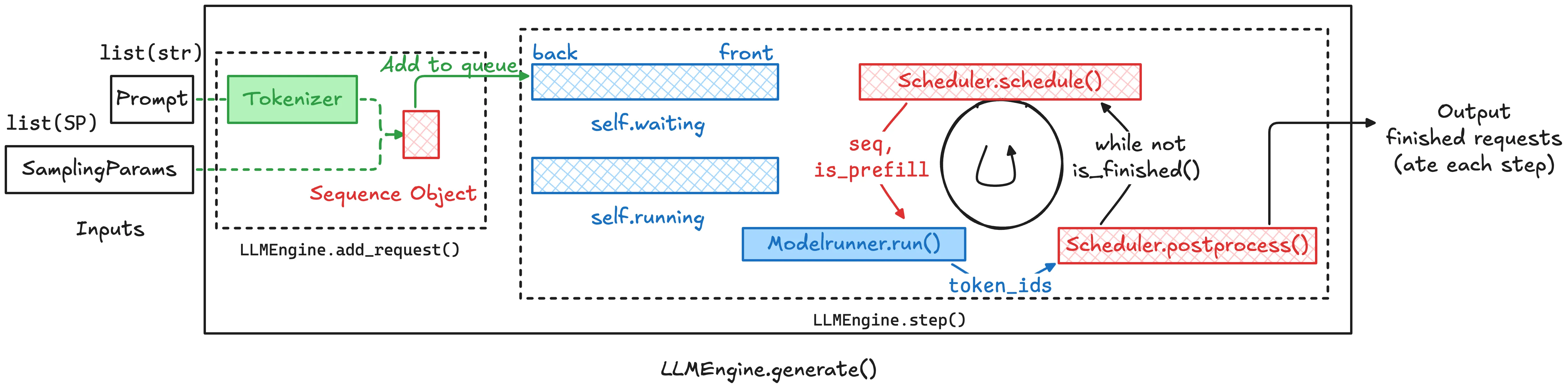
总结我们在 Scheduler 中需要实现的 API:
add():将请求添加到 waiting queue 中is_finished():Scheduler 停止运行条件schedule():在每一轮决定:哪些 sequence 参与执行?这一轮属于 prefill 还是 decode batch?postprocess()在每一轮前向计算完成之后更新序列状态,例如追加生成 token,更新状态,维护 KV Cache 等
Scheduler 类实现
本小节对应 Nano vLLM 的
class Scheduler,点击链接跳转。
class Scheduler:
def __init__(self, config: Config):
self.max_num_seqs = config.max_num_seqs
self.max_num_batched_tokens = config.max_num_batched_tokens
self.eos = config.eos
self.block_manager = BlockManager(config.num_kvcache_blocks, config.kvcache_block_size)
self.waiting: deque[Sequence] = deque()
self.running: deque[Sequence] = deque()Scheduler 主要使用两个 deque 管理请求:
waiting:所有还需要做 prefill 的请求(包括:还没开始、chunked prefill 中、以及被抢占后需要继续 prefill 的)running:已经完成 prefill、进入 decode 阶段的请求
新请求统一加入 waiting 队尾。 在调度过程中,prefill 阶段通常按 FIFO 顺序从队首选择请求进行处理;但在 decode 阶段,running 队列更像一个活跃集合,其调度不严格遵循 FIFO,而是根据 batching 和完成情况动态更新。
同时,Scheduler 内部维护了一个 BlockManager,用于对系统中的 KV Cache Blocks 进行统一的逻辑管理。为了简化说明,这里仅通过其对外提供的 API 来理解其行为,具体实现细节可参考 Nano vLLM 解读(4):解析 BlockManager。
添加 Sequence 和判断终止条件函数
下面观察源码是如何实现 add(), is_finished().
add(),被上层LLMEngine.add_request()调用,加入 Scheduler waiting queueis_finished()当两个 deque 都空时返回 True
class Scheduler:
def is_finished(self):
return not self.waiting and not self.running
def add(self, seq: Sequence):
self.waiting.append(seq)调度逻辑和后处理函数
下图展示了 Scheduler.schedule() 和 Schedule.postprocess() 的核心逻辑。
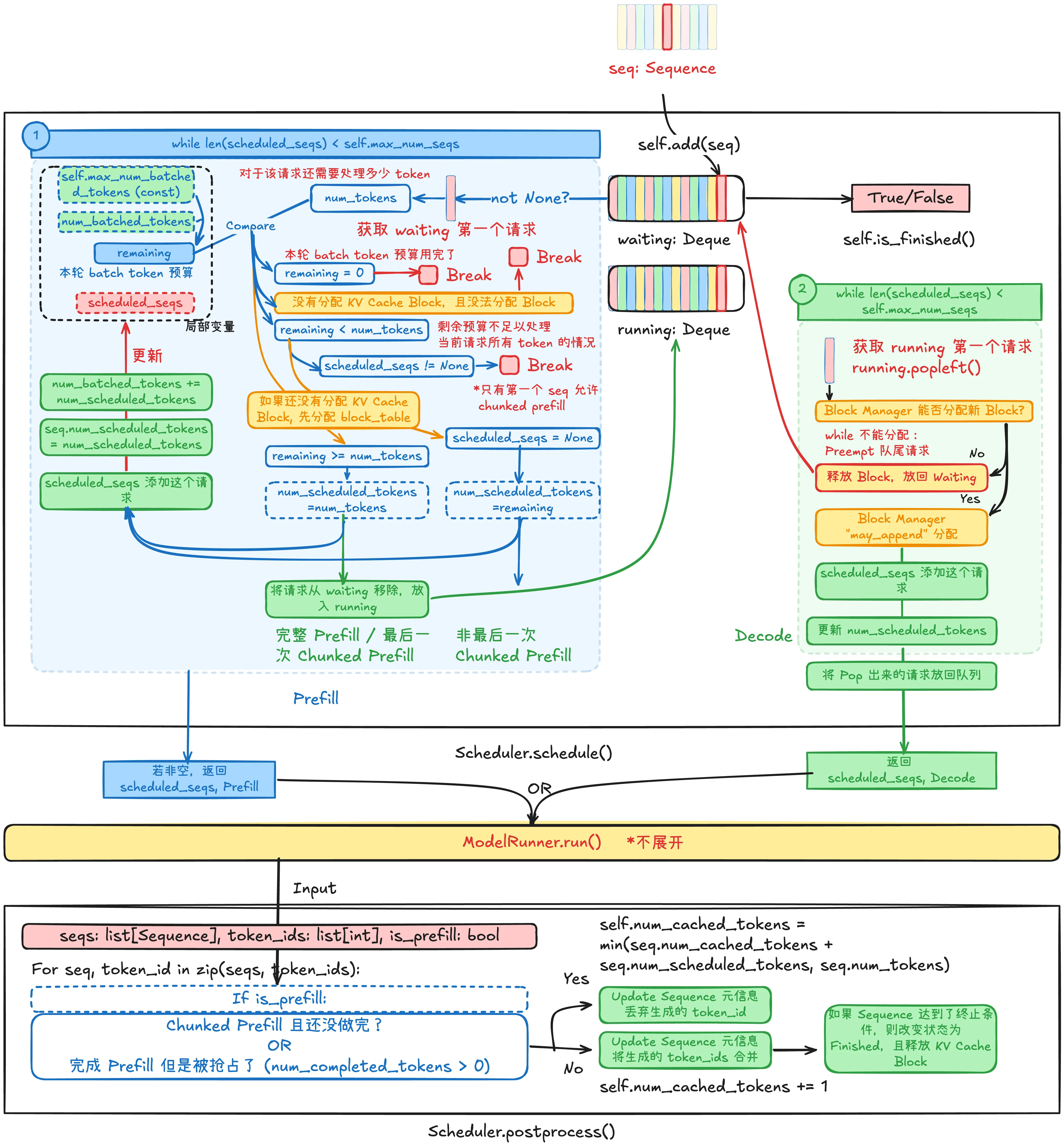
Scheduler 调度特性和核心 pipeline
Nano-vLLM Scheduler 的核心特性:
- 阶段式调度(Phase-based)
- Prefill 和 Decode 不混跑
- 只有当
waiting为空时才进入 Decode - 这是为了避免 compute-bound 与 memory-bound workload 冲突
- 资源约束调度:
- 单轮能跑的请求数量由
self.max_num_seqs限制 - 单轮能跑的 token 数量由
self.num_batched_tokens限制
- 单轮能跑的请求数量由
- Prefill 调度策略:
- 按照
waitingqueue 顺序处理 - 对每个请求:
- 如果 token budget 足够则做完整 prefill
- 否则做 Chunked Prefill
- 限制只有一个请求能够触发 Chunked Prefill,剩下的则不允许
- 按照
- Decode 阶段策略:continuous batching
Scheduler.schedule() 函数整体流程:在每个 step 只会调度一种阶段:Prefill 或 Decode(二选一),执行流程如下:
- 优先尝试从
waitingqueue 中调度 Prefill - 如果本轮成功调度了至少一个 Prefill 请求,则立即返回,进入 Prefill 阶段
- 只有当本轮没有任何 Prefill 被调度成功时,才进入 Decode 阶段
- 返回:
scheduled_seqs:本轮执行的请求is_prefill:是否为 Prefill 阶段
schedule 函数维护两个局部变量:
scheduled_seqs即本轮被选中调度的请求num_batched_tokens当前 batch(即当前轮所选中调度的请求)已经占用的 token 预算
class Scheduler:
def schedule(self) -> tuple[list[Sequence], bool]:
scheduled_seqs = []
num_batched_tokens = 0
# prefill
while self.waiting and len(scheduled_seqs) < self.max_num_seqs:
seq = self.waiting[0]
# (1-1)
num_tokens = max(seq.num_tokens - seq.num_cached_tokens, 1)
remaining = self.max_num_batched_tokens - num_batched_tokens
# (1-2)
if remaining == 0 or (not seq.block_table and not self.block_manager.can_allocate(seq)): # no budget
break
if remaining < num_tokens and scheduled_seqs: # only allow chunked prefill for the first seq
break
# (1-3)
if not seq.block_table:
self.block_manager.allocate(seq)
# (1-4)
seq.num_scheduled_tokens = min(num_tokens, remaining)
if seq.num_scheduled_tokens == num_tokens:
seq.status = SequenceStatus.RUNNING
self.waiting.popleft()
self.running.append(seq)
scheduled_seqs.append(seq)
num_batched_tokens += seq.num_scheduled_tokens
# 如果这轮成功调度了至少一个 prefill 请求则立即返回
if scheduled_seqs:
return scheduled_seqs, True
# decode
while self.running and len(scheduled_seqs) < self.max_num_seqs:
seq = self.running.popleft()
# (2-1)
while not self.block_manager.can_append(seq):
if self.running:
self.preempt(self.running.pop())
else:
self.preempt(seq)
break
# (2-2)
else:
seq.num_scheduled_tokens = 1
self.block_manager.may_append(seq)
scheduled_seqs.append(seq)
assert scheduled_seqs
self.running.extendleft(reversed(scheduled_seqs))
return scheduled_seqs, False
def preempt(self, seq: Sequence):
seq.status = SequenceStatus.WAITING
self.block_manager.deallocate(seq)
self.waiting.appendleft(seq)Scheduler Prefill 阶段
在 Prefill 阶段,只要 waiting queue 非空且 scheduled_seqs 数量没有达到 Scheduler 限制,就持续检查 waiting 队首请求(FIFO)。
(1-1)首先计算当前请求本轮还需要处理的 token 数 num_tokens,以及当前 batch 剩余的 token 预算 remaining。这里的 num_tokens 不是该请求的完整 token 数,而是 尚未完成 Prefill 的 token 数。
(1-2)有以下几种情况会终止 Prefill 调度:
- 当前 batch 已经没有剩余 token 预算;
- 当前请求还没有分配过 KV Cache,而 Block Manager 也无法为它分配初始的 KV Cache Block;
- 当前请求无法完整执行 Prefill,且本轮 batch 中已经调度了其它请求。换句话说,只有 batch 中的第一个请求允许做 chunked prefill。
经过(1-2)之后,就说明当前队首请求可以被成功调度。
(1-3)如果该请求还没有 block_table,则先为其分配 KV Cache Block;如果它是之前已经开始过的 chunked prefill 请求,则不需要重复分配。
(1-4)随后确定本轮实际调度的 token 数:
- 若本轮只能执行部分 Prefill,则该请求继续保留在
waiting队列中,下一轮仍然优先参与 Prefill; - 若本轮完成了全部剩余 Prefill,则将其状态设为
RUNNING,并将其从waiting队列移动到running队列; - 最后更新
scheduled_seqs和num_batched_tokens。
如果这一轮成功调度了至少一个 Prefill 请求,则立即返回,不再进入 Decode 阶段。因此 Nano-vLLM 的这个 Scheduler 不会在同一轮中混合执行 Prefill 和 Decode。
Scheduler Decode 阶段
只有当这一轮没有任何 Prefill 请求被调度时,Scheduler 才会进入 Decode 阶段。
在 Decode 阶段,只要 running queue 非空且 scheduled_seqs 数量没有达到 Scheduler 限制,就持续从 running 队首取出请求尝试调度。
(2-1)首先调用 BlockManager.can_append() 检查当前请求是否还能继续向 KV Cache 追加一个新 token。如果不能,则需要通过抢占释放空间:
- 如果
running队列中还有其它请求,则抢占队尾请求; - 被抢占的请求会释放已有的 KV Cache,并被重新放回
waiting队列队首,状态也改回WAITING; - 如果当前请求已经是最后一个可用请求,仍然无法 append,则连当前请求自己也会被抢占,并终止本轮 Decode 调度。
(2-2)一旦确认当前请求可以成功 append,则将其本轮待处理 token 数设为 1,并调用 BlockManager.may_append(seq),为该请求本轮追加的 1 个 token 预留或更新 KV Cache 的 block 状态(KV 的实际写入是在 ModelRunner 执行 forward 时完成)。然后把它加入本轮的 scheduled_seqs。
在 Decode 调度结束后,这些成功调度的请求会按原顺序重新放回 running 队列前部,从而继续参与之后的 Decode step。如果有请求达到了终止条件需要退出 Decode,由 Scheduler 后处理阶段将其移出 running queue 并更改其状态为 FINISHED.
Scheduler 后处理
在 ModelRunner 完成一轮推理之后,会返回 seqs 中每个 sequence 对应的一个 token_id。 但这个 token_id 不一定都会被作为正式输出拼接回 seq 中:在 Chunked Prefill 的中间阶段,返回的 token_id 只是一轮前向计算的副产物,并不表示该请求已经完成了基于完整上下文的下一 token 生成,因此不会被写回 sequence(详见 Chunked Prefill)。
Scheduler.postprocess() 的主要作用,是根据本轮执行结果更新每个 sequence 的状态。对于每一组 (seq, token_id),其逻辑大致如下:
- 如果当前是 Prefill 阶段,则先更新
seq.num_cached_tokens,表示本轮有多少输入 token 已经被写入 KV Cache - 如果当前仍处于 Chunked Prefill 的中间阶段,或者该请求是被抢占后重新执行 Prefill,则本轮返回的
token_id不会被当作正式生成结果拼接到seq中;此时只需清空seq.num_scheduled_tokens并继续处理下一个请求 - 否则,说明该请求在本轮确实生成了一个有效的新 token,于是:
- 调用
seq.append_token(token_id)将其拼接到 sequence 中 - 更新
seq.num_cached_tokens += 1,表示生成了一个新的 output token - 将
seq.num_scheduled_tokens清零
- 调用
- 检查该请求是否满足终止条件,例如:
- 新生成的 token 是
eos - 已达到最大生成长度
max_tokens
- 新生成的 token 是
- 如果请求结束,则:
- 将其状态标记为
FINISHED - 释放其占用的 KV Cache blocks
- 将其从
runningqueue 中移除
- 将其状态标记为
解释:Prefill 分支的 num_cached_tokens 分成两次更新:
- 先加
seq.num_scheduled_tokens:表示这轮前向计算中,多少个已有输入 token 被处理并写入了 KV cache - 若本轮恰好完成 Prefill 并生成首个有效 output token,则额外 +1,因为该 token 也已写入 KV cache。
解释:running queue 不是按顺序(FIFO)弹出请求的。这很容易理解,因为所有 Sequence 的终止条件有可能不同,有的请求可能提前生成 eos 字符退出推理。
class Scheduler:
def postprocess(self, seqs: list[Sequence], token_ids: list[int], is_prefill: bool):
for seq, token_id in zip(seqs, token_ids):
# (1)
if is_prefill:
seq.num_cached_tokens = min(seq.num_cached_tokens + seq.num_scheduled_tokens, seq.num_tokens)
# (2)
if seq.num_cached_tokens < seq.num_tokens or seq.num_completion_tokens > 0: # chunked prefill or re prefill after preemption
seq.num_scheduled_tokens = 0
continue
# (3)
seq.append_token(token_id)
seq.num_cached_tokens += 1
seq.num_scheduled_tokens = 0
# (4)
if (not seq.ignore_eos and token_id == self.eos) or seq.num_completion_tokens == seq.max_tokens:
# (5)
seq.status = SequenceStatus.FINISHED
self.block_manager.deallocate(seq)
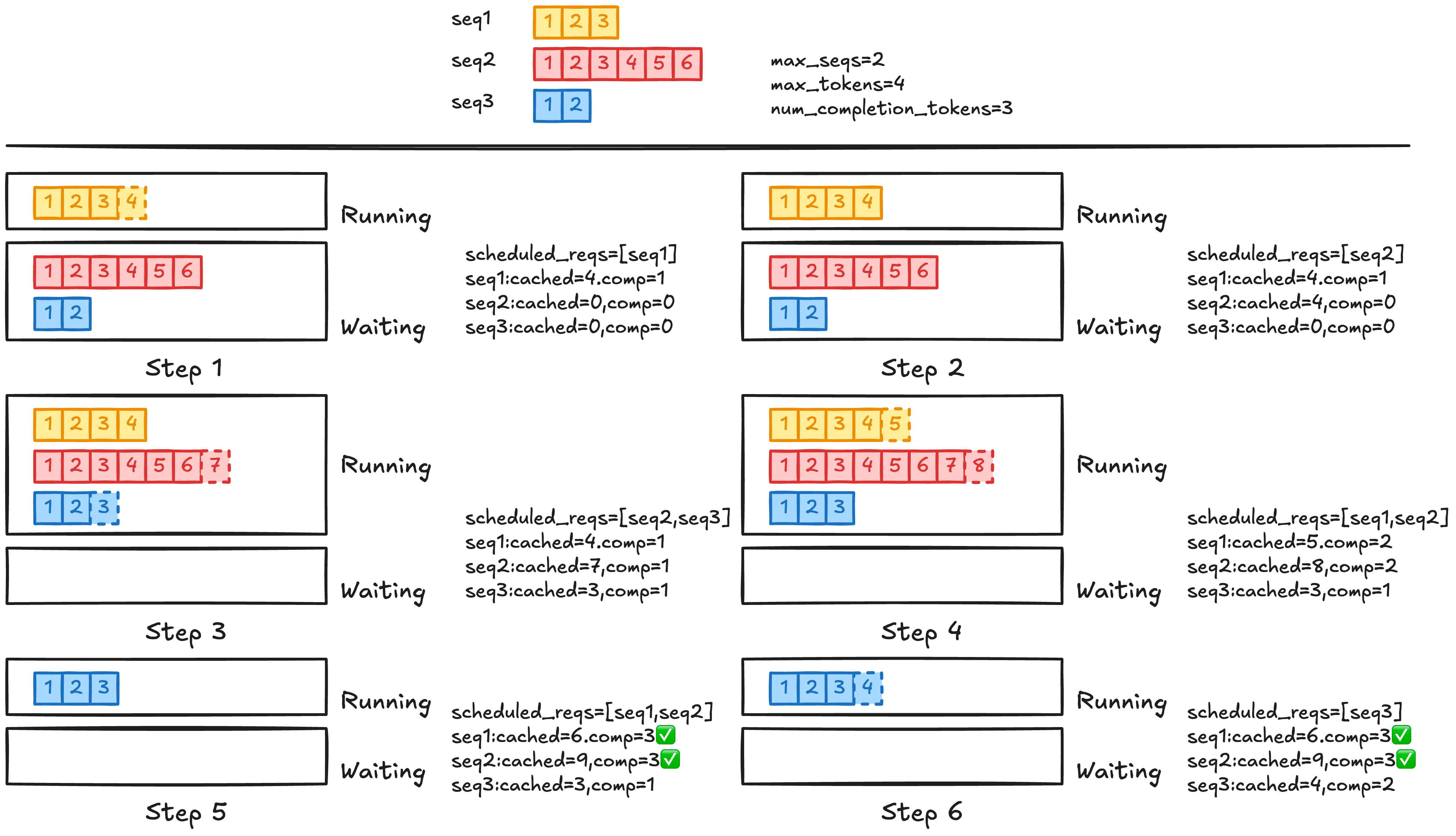
self.running.remove(seq)多个请求的逐 step 执行演化过程
下图展示了三个请求从进入系统到完成生成的逐步执行过程。每一个 step 表示一次模型执行(forward)结束后的系统状态。