Paged Attention:高效管理 KV Cache
1 min
TBD:未来将会增加更多细节
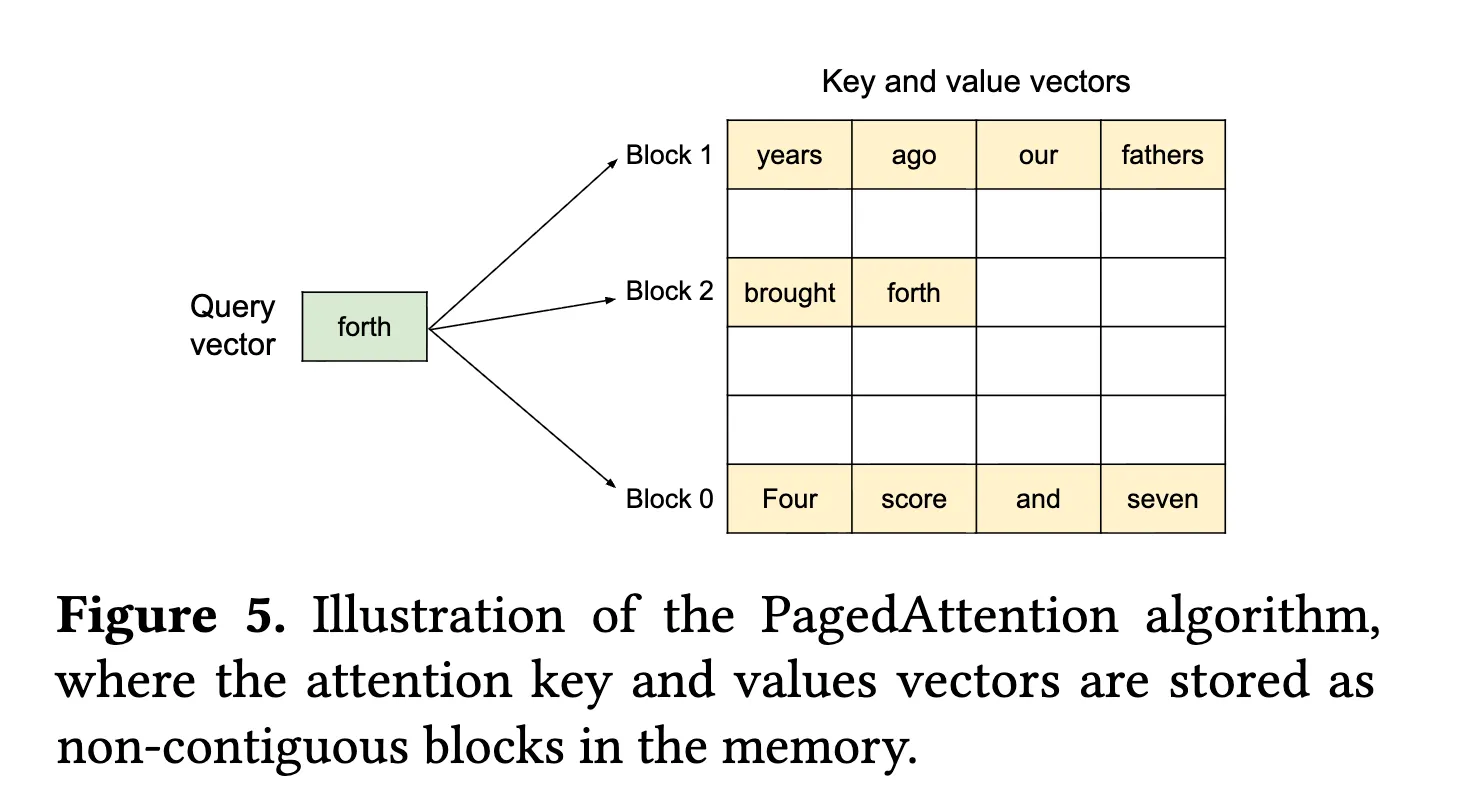
NOTEPaged Attention 使用类似虚拟内存分页的管理方式,使得 KV Cache 可以按需分配与回收,从而有效降低显存碎片化并提高内存利用率。
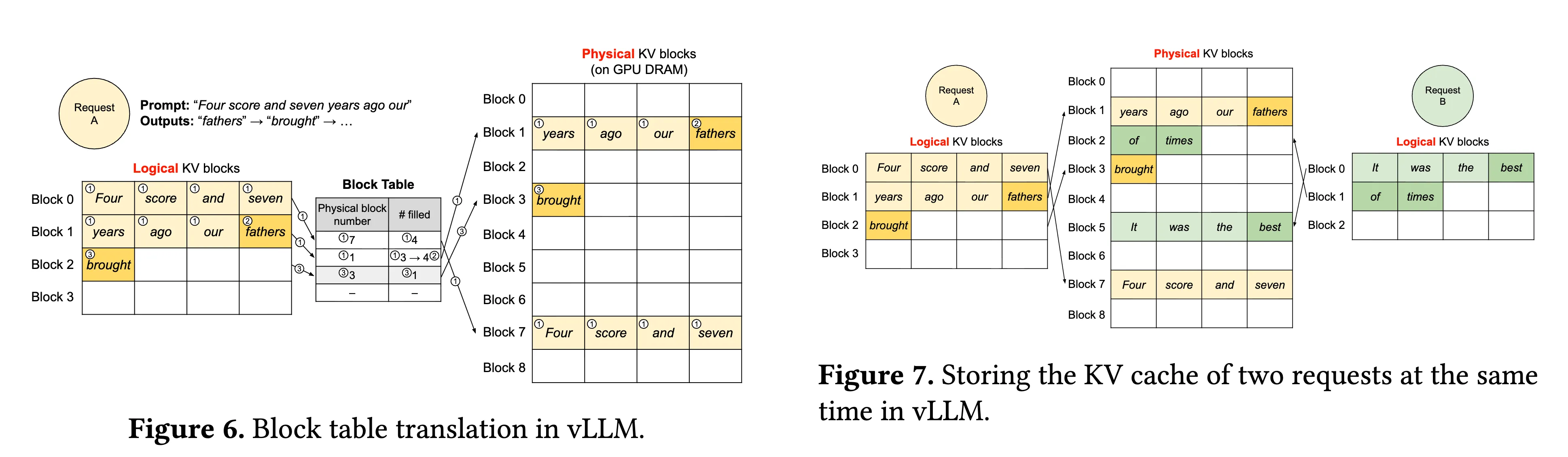
PagedAttention 是由 vLLM1提出的,将 KV Cache 按固定大小的 Block 进行划分,每个 Block 存储若干连续 token 的 KV 表示。对于单个请求,其 KV Cache 由多个 Block 组成,并通过逻辑到物理 Block 的映射表进行管理。
在 Paged Attention 中,每个请求维护一组 Logical KV Blocks,可类比为该请求的“虚拟页表”。这些 Logical Blocks 并不直接对应连续的物理显存,而是映射到全局内存池中的 Physical KV Blocks(固定大小的物理块)。
系统通过维护一张 Block Table,记录每个请求的 Logical KV Block 与 Physical KV Block 之间的映射关系。在访问 KV Cache 时,请求首先根据自身的逻辑块编号查找 Block Table,再定位到对应的物理块,从而完成对实际显存的访问。