大模型推理并行策略:DP/TP/SP/PP
TLDR
为了突破单设备的计算与内存瓶颈,大模型推理通常通过并行化计算与数据分布来提升吞吐和降低延迟。
给定 hidden states 的形状为 :
- :batch size
- :sequence length
- :hidden dimension
可以从不同维度对计算进行切分,对应不同的并行策略:
按张量维度切分
- DP (Data Parallel, 数据并行):切分 不同样本之间相互独立,因此可以直接分配到不同设备上,几乎不需要通信(推理阶段尤其如此)。
- TP (Tensor Parallel, 张量并行):切分 将一个大矩阵乘法拆分到多个设备上执行,本质是对算子(如 GEMM)进行并行化,需要在计算过程中进行通信(如 all-reduce / all-gather)。
- SP (Sequence Parallel, 序列并行):切分 将序列维度分布到不同设备上,可以降低 activation 内存占用。但在 attention 计算中,由于 token 之间存在依赖,需要进行跨设备的通信(如 all-gather 或 reduce-scatter)。
按模型结构切分
- PP (Pipeline Parallel, 流水线并行):切分模型层(layer-wise) 将模型的不同层分布到不同设备上,每个设备负责一部分前向计算。多个输入可以以“流水线”的方式依次通过这些设备,从而提高设备利用率。
DP 实现
将输入数据沿 维度切开,在每个 rank 上都储存模型完整的权重,每个 rank 独立处理用户请求。
DP 与开多个推理实例并发处理的区别在于:
- DP 由同一个推理实例管理
- 这意味着共享一个全局 scheduler,对请求进行统一调度与 batching
参考文章:ZeRO 和 FSDP:DP优化——将模型参数和中间状态分片到多卡
TP 实现
如何切分 MLP 层和 Attention 层模型权重或者输入矩阵:MegatronV1
参考论文:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
基于 矩阵乘法并行化 所提到的思想,我们将模型权重进行拆分。下图分别展示了在 MLP 层和在 Self-Attention 层的模型权重拆分方法。
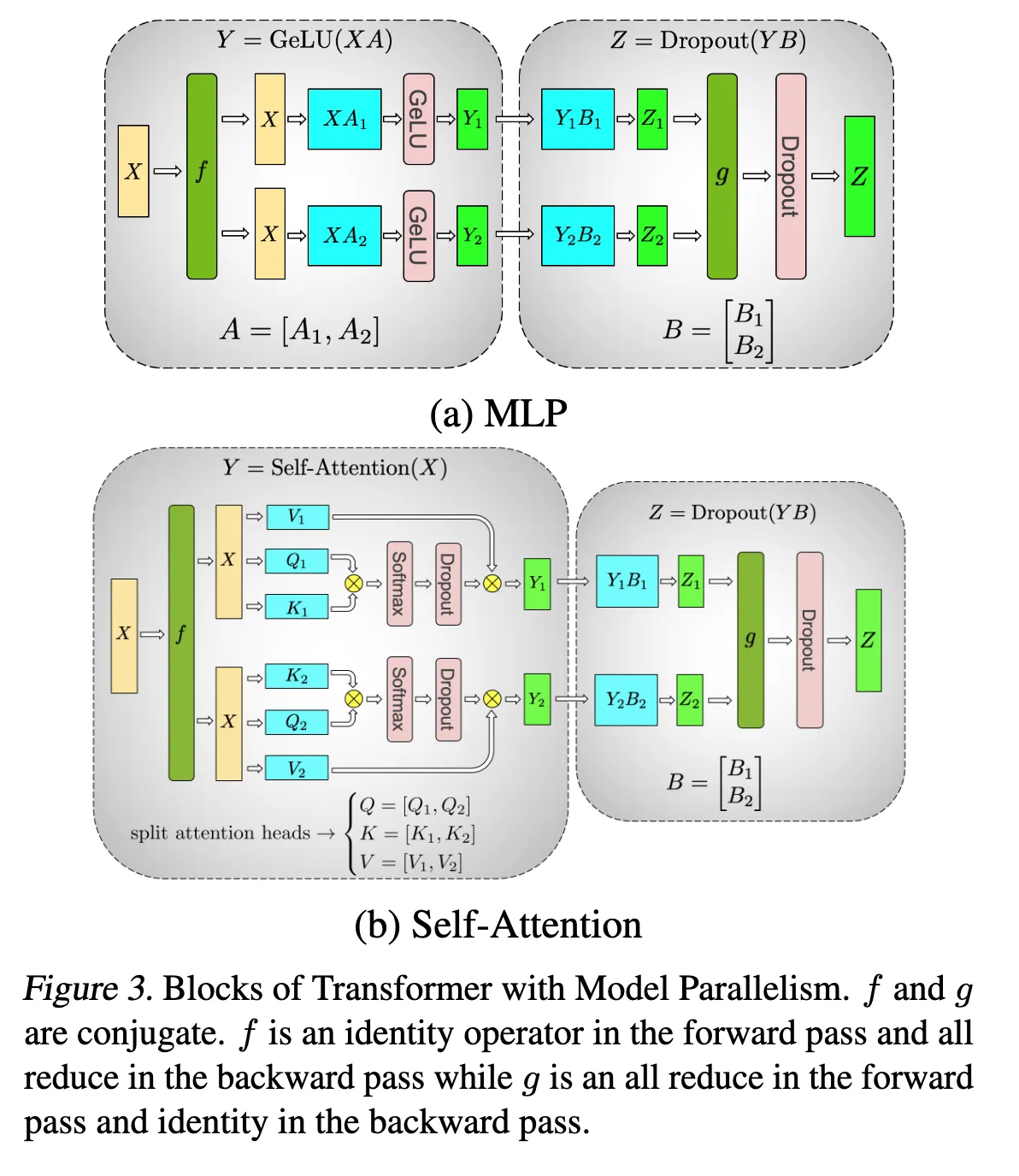
MLP 层模型权重拆分
假设 是 activation 输入, 和 分别是升维和降维矩阵, 是非线性函数,通常是 GELU,因此 MLP 层可以被建模为下面的计算:
这个操作可以理解为三个矩阵乘法中间插入一个 函数。
- 观察到 (由于非线性), 因此若对求和维(内积维)进行拆分,则必须在非线性之前进行一次同步(如 All-Reduce),否则会导致计算结果错误。
- 因此我们:列切 矩阵,行切 矩阵。推导请见 三个矩阵乘法:
- 图中的 与 是一对共轭通信算子:
- 在前向为恒等映射,在反向执行 All-Reduce;
- 在前向执行 All-Reduce,在反向为恒等映射;
Self-Attention 层模型权重拆分
设输入 ,多头注意力包含对 的线性投影以及输出投影。记:
Self-Attention 可以表示为:
- 对 的线性投影采用列并行(column parallel),即按输出维度(head 维度)切分权重矩阵:
- 输出投影矩阵 采用行并行(row parallel),以对齐前一步的切分结果:
- 图中的 与 同样构成一对共轭通信算子:
- 在前向为恒等映射,在反向执行 All-Reduce;
- 在前向执行 All-Reduce,在反向为恒等映射;
NOTETP 和多头的关系:TP 对 矩阵进行列切分,沿 hidden dimension 分布到不同设备上。Multi-head attention 本质上将 hidden dimension(即沿着列方向)划分为多个独立的 head,每个 head 的计算相互独立。因此,这两者天然可以结合:TP 可以直接利用 multi-head 的结构,将不同的 attention head 分配到不同的设备上,使得每个 rank 负责若干个 head 的计算,从而实现无通信的并行计算。
总结
如下图所示,一层 Transformer Layer 前向推理包含两次 All-Reduce 通信,Attention Block 一次,MLP Block 一次。
![]()
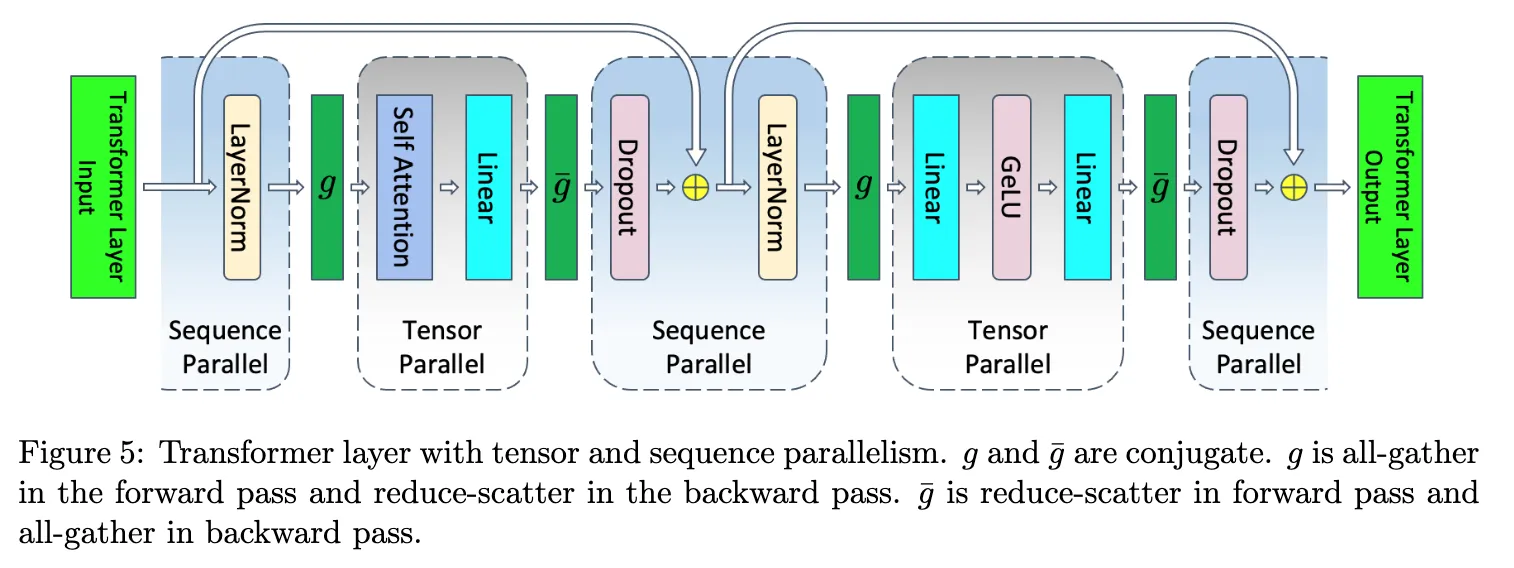
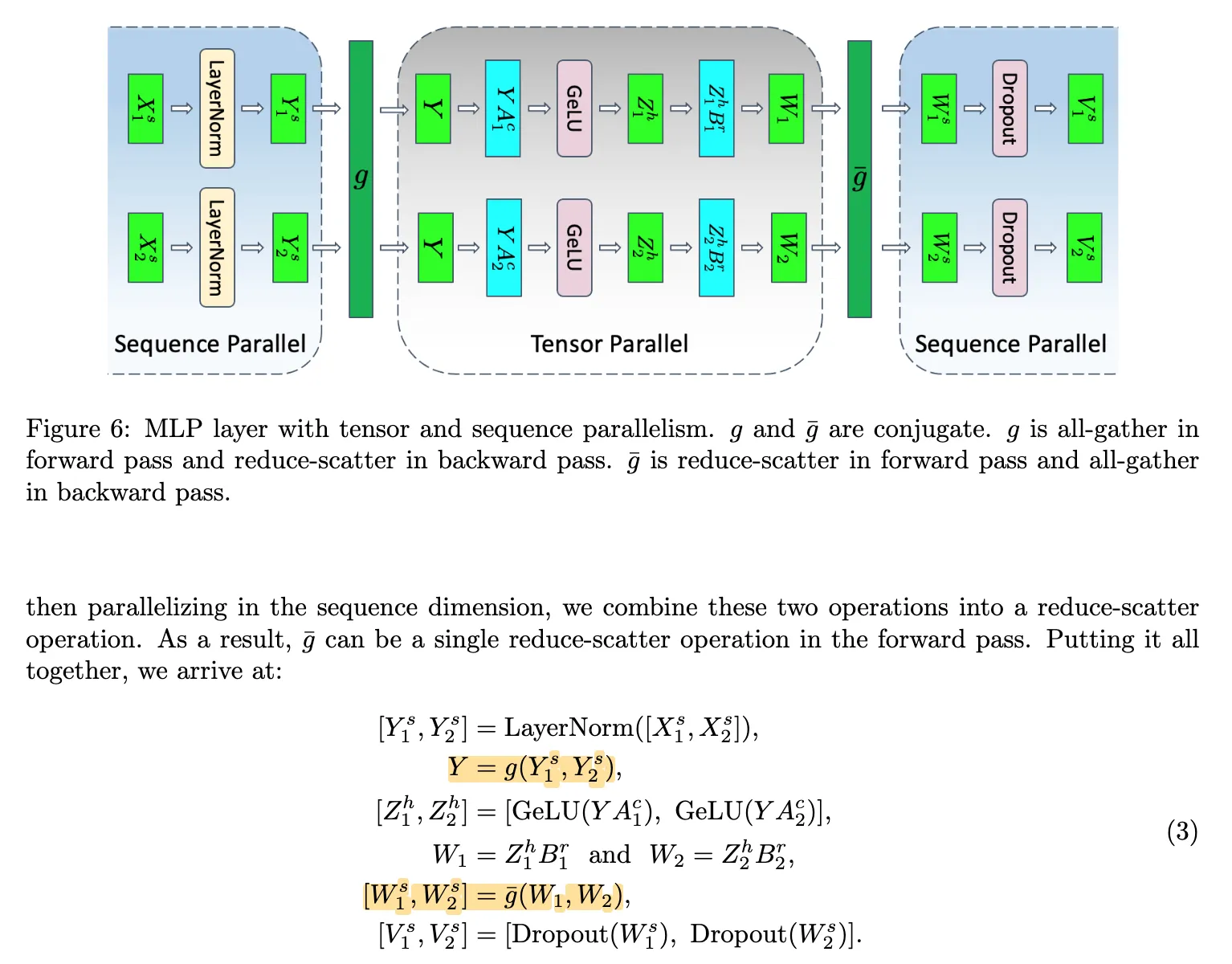
SP 实现
MegatronV3:Attention 和 MLP Block 之外的序列并行
参考论文:Reducing Activation Recomputation in Large Transformer Models
对于 Attention Block 和 MLP Block 之外的操作(如 LayerNorm 和 Dropout),其计算在 sequence 维度上是相互独立的。 因此,可以沿 sequence 维度 对 activation 进行切分,从而避免在 tensor parallel 组内的重复存储,降低中间激活的显存开销。
下图展示了在 TP 基础上做 SP 的实现。其中在前向推理时, 是 All-Gather, 是 Reduce-Scatter:
- :Sequence Parallel 的输出是沿 sequence 维度切分的 activation 。当后续算子(如 Attention)需要访问完整 sequence 时,需要通过 All-Gather 恢复完整的 activation 。
- :Tensor Parallel 在计算过程中会产生分布在各个设备上的部分结果(partial results)。在传统 TP 中,这些结果通过 All-Reduce 聚合为完整输出;而在 TP + SP 结合时,可以将该过程改写为 Reduce-Scatter,从而直接得到按 sequence 切分的结果 ,供后续 SP 使用。
DeepSpeed Ulysses:Attention Block 的序列并行
参考这篇 Blog:DeepSpeed Ulysses:Attention Block 的序列并行
PP 实现
并行度分配
- DP与 SP/TP 可以解耦独立使用
- SP 与 TP 一般可以配合使用
- 一般设计成:DPTP=world_size,SP=TP
当单卡无法容纳模型时,可以在单机内部使用 TP 来切分矩阵计算,因为这种方式依赖高带宽、低延迟的互联;在跨机器场景下,更适合使用 PP 来按层切分模型,从而减少频繁的跨节点通信;也可以使用 ZeRO-3 或 FSDP,将参数、梯度和优化器状态分片存储在不同设备上。
当模型已经能够顺利运行之后,接下来的目标才是提升训练吞吐,此时再通过 DP 来扩展规模,将 batch 切分到更多设备上,从而充分利用计算资源。整体思路可以理解为:先解决“能不能放下”,再解决“跑得快不快”。