Ring Attention:Attention Block 的序列并行
在长上下文场景下,序列并行(Sequence Parallelism)通常用于切分 seq_len 维度。然而 Attention 计算具有全局依赖性:每个 Query 都需要访问完整的 KV 序列,这使得序列维度上的直接切分变得困难。同时,在长序列场景下,单个设备往往无法容纳完整的 KV Cache,因此需要对 KV 进行分布式存储1。在序列并行下,需要先 AllGather 从所有设备收集完整 KV Cache,再在本地算局部 Q shard 的 attention 计算。
为了解决这一问题,Ring Attention 在 Attention 计算过程中将 AllGather 操作替代为使用 ring 通信机制 在设备之间轮转 KV 块,采用 blockwise / online softmax 的方式完成 Attention 计算。
参考论文:Ring Attention with Blockwise Transformers for Near-Infinite Context
回顾
Attention 计算:
Attention 在每一行(每个 query)切分 不影响计算结果正确性。
Ring Attention 思路
下图是论文里关于 Ring Attention workflow 的表述: 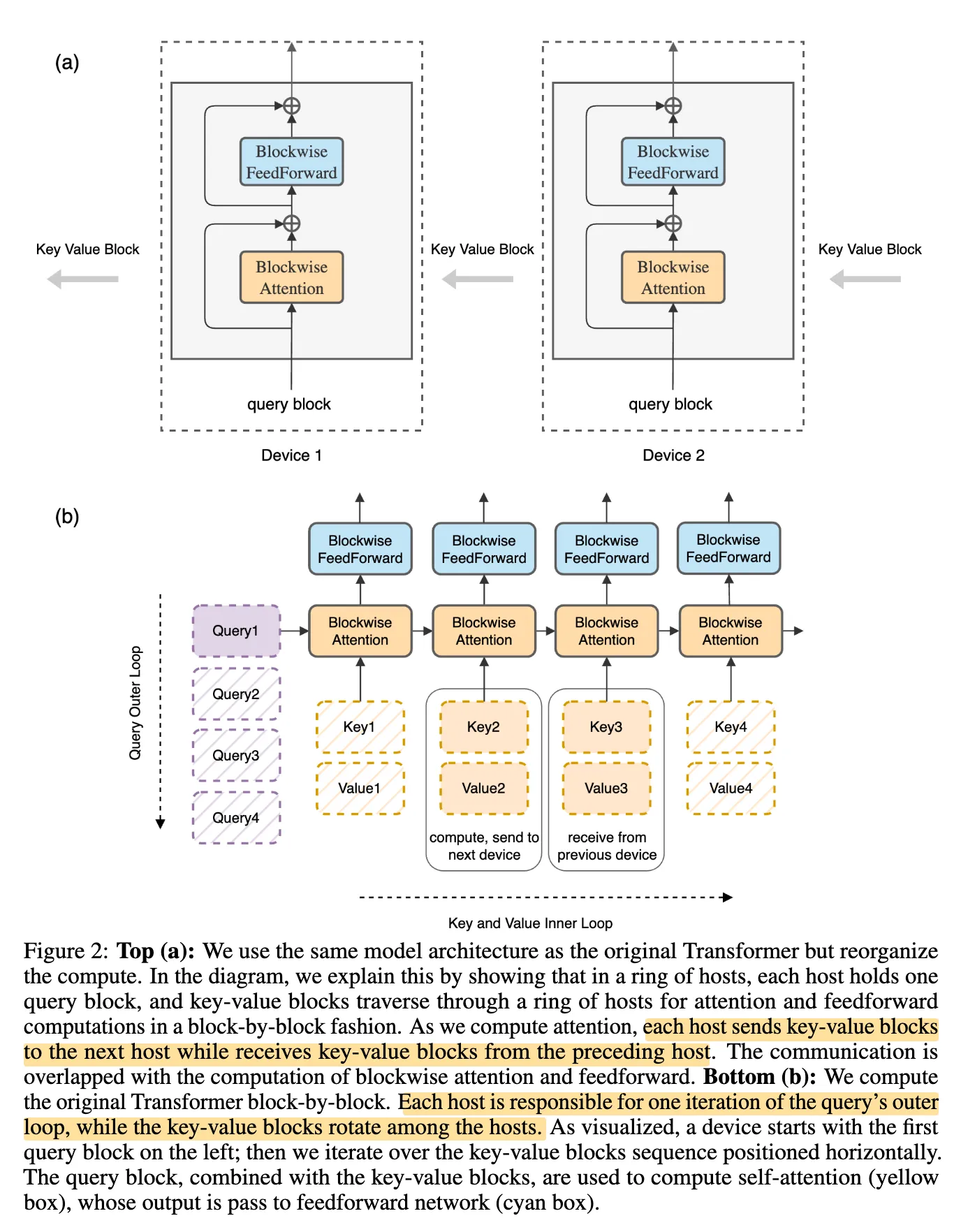
注:由于不同 Q shard 之间不存在依赖关系,该过程在 Query 维度上是 embarrassingly parallel 的。
假设我们有 个 rank,每个 rank 持有一部分的 . 对于任意 ,都需要与完整的 进行计算。
- 每个 rank 固定持有自己的
- 将 按序列维度分块分布在各个 rank 上,并采用 ring 通信方式在 个 step 中轮转这些 块
- 并在 个 step 中 依次接收不同 rank 的 块
- 基于 blockwise / online softmax,在逐块处理 KV 的过程中对 Attention 结果进行累积,从而在不访问完整 KV 的情况下,得到与全局 softmax 等价的 Attention 输出。(参考 Online Softmax 推导)
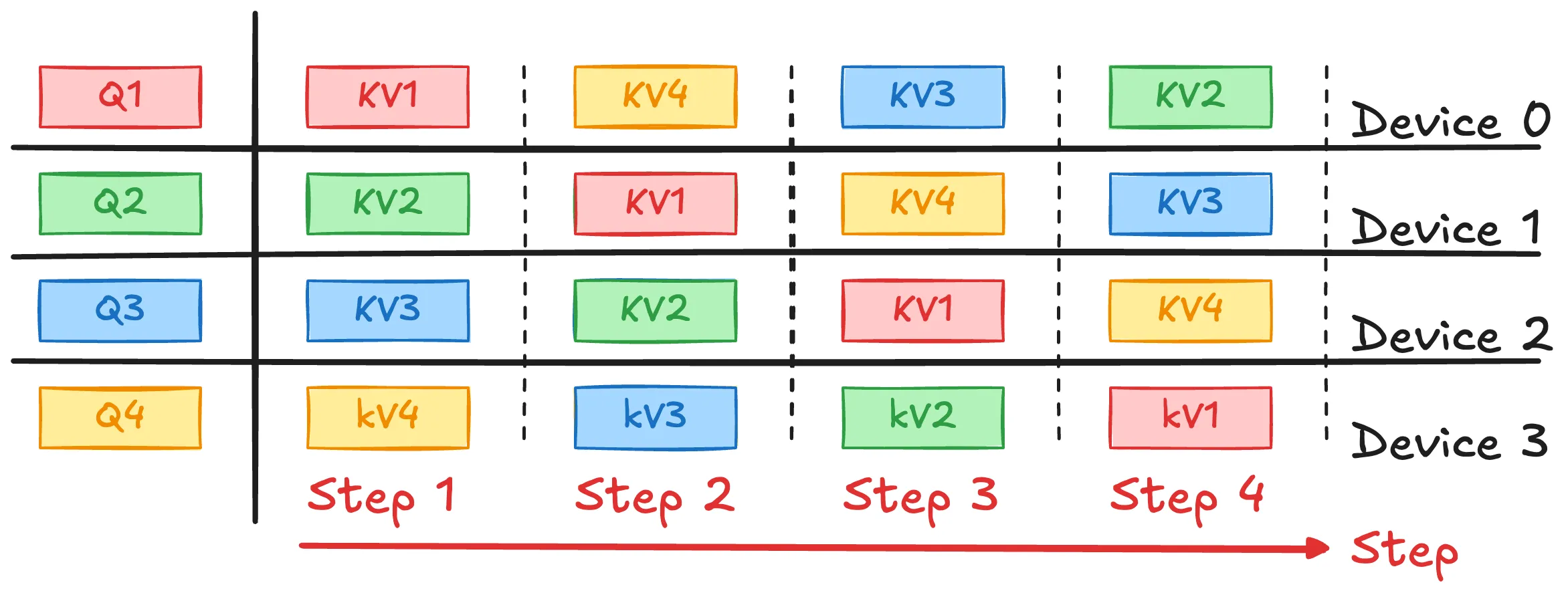 由于块计算比块传输需要更长的时间,与标准 Transformer 相比,此过程不会增加开销。
由于块计算比块传输需要更长的时间,与标准 Transformer 相比,此过程不会增加开销。
RingAttention 仅需要一个非常小的环形拓扑,并且支持 GPU 和 TPU。最小块大小由 FLOPs/单向带宽决定,可以很容易实现。