Roofline Model 用于衡量一个运算 / kernel 在特定计算平台(例如 GPU 或 TPU)上是计算受限(compute-bound)还是内存受限(memory-bound)。任何一个计算过程都同时受到计算能力和内存带宽两方面的约束,最终性能由两者中较小值决定。Roofline 模型不仅可以判断算子/模型的 Arithmetic Intensity 是否过低(导致 memory-bound),更重要的是用于定位性能瓶颈,指导优化方向。
计算平台指标
FLOPs 和 FLOP/s (FLOPS) 定义。为了避免混淆,我们先对这两个变量进行定义:
- FLOPs(Floating Point Operations) 表示浮点运算的总数量,是一个“工作量”的概念。例如,一个矩阵乘法需要执行多少次乘加操作,这个总次数就是 FLOPs。
- FLOP/s(或 FLOPS) 表示每秒可以执行多少次浮点运算,是一个“速度”或“吞吐”的概念。它描述的是“硬件一秒钟能做多少计算”
算力 (Compute Throughput):计算平台的计算性能上限,表示平台单位时间内最多可以执行多少浮点运算,单位是 FLOPS 即 FLOP/s.
π=Peak FLOPS带宽 (Memory Bandwidth):计算平台的带宽上限,定义为单位时间(1s)能从内存中读取或写入多少数据,单位是 Bytes/s.
β=Peak Memory BW (Bytes/s)Roofline 模型
Roofline 模型希望回答:
- 一个特定的运算 / kernel 或者模型,其访存量为 m Bytes,计算量为 c FLOPs
- 在特定计算平台上,其中该计算平台算力为 π,带宽为 β
- 其理论性能上限是多少
一个运算的性能上限,本质上由计算能力和访存能力共同决定。
- 从计算角度看,如果数据可以被无限快地提供,那么运算平台的峰值算力 π 决定了每秒最多可以执行多少浮点运算(FLOPs),这是纯粹的计算上限。
- 然而在实际系统中,计算必须依赖于数据从内存中加载,因此性能往往还会受到访存能力的限制。
最大访存能力推导:
- 带宽决定:首先因为带宽受限,运算平台在单位时间内最多能准备多少数据量(单位:Bytes/s)?
- 算法决定:单位数据(1 Byte)需要执行多少 FLOPs 运算,这一部分是由模型决定的。我们将其定义为算术强度 (Arithmetic Intensity) I(FLOPs/Bytes)
- 两者结合在一起即为在访存限制下系统每秒最多能够支撑的计算量
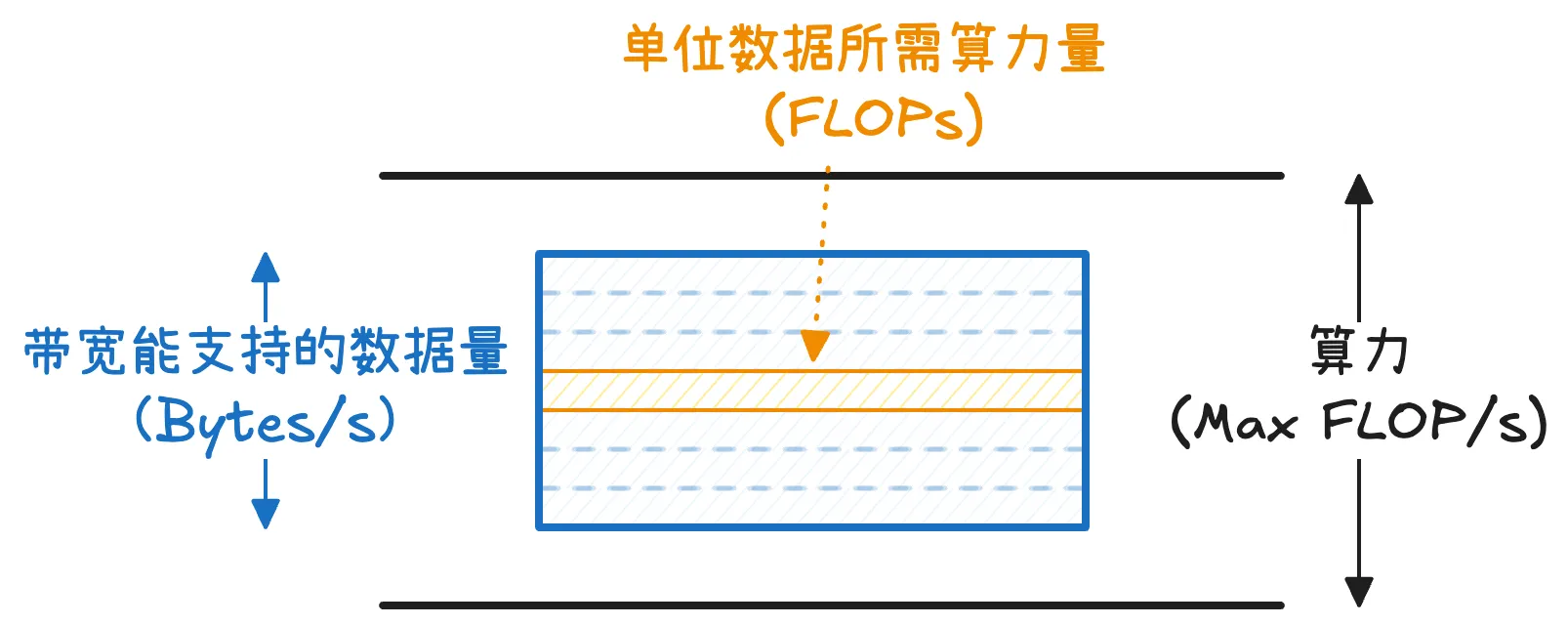 带宽决定了每秒能拿到多少数据,算术强度决定每单位数据需要执行多少运算,两者乘法即带宽所能支撑的最大计算能力,但最终还是受到算力上限的限制。
带宽决定了每秒能拿到多少数据,算术强度决定每单位数据需要执行多少运算,两者乘法即带宽所能支撑的最大计算能力,但最终还是受到算力上限的限制。因此:一个运算的实际性能上限应当是计算能力和访存能力两者中的较小值
Achieved Performance (FLOPS)=min(Peak FLOPS,Arithmetic Intensity×Peak Memory BW)=min(π,Iβ)- 当 π>Iβ,说明计算平台是内存受限(饥饿)。此时有两种可能:第一种计算平台的带宽比较差,第二种是运算/模型的每单位数据 FLOPs 运算量太小,需要优化
- 当 π<Iβ 时,说明计算平台是计算受限的(太累),此时该算子具有较高的算术强度,能够充分利用计算资源。优化方向是降低计算量(量化、剪枝等)
同时,算术强度上限定义了模型在当前平台下,单位数据可以达到的理论执行 FLOPs 运算量的最大值
I≤Imax=βπ基于以上分析可以画出以下图像,其中 P=Achived Performance (FLOPS). 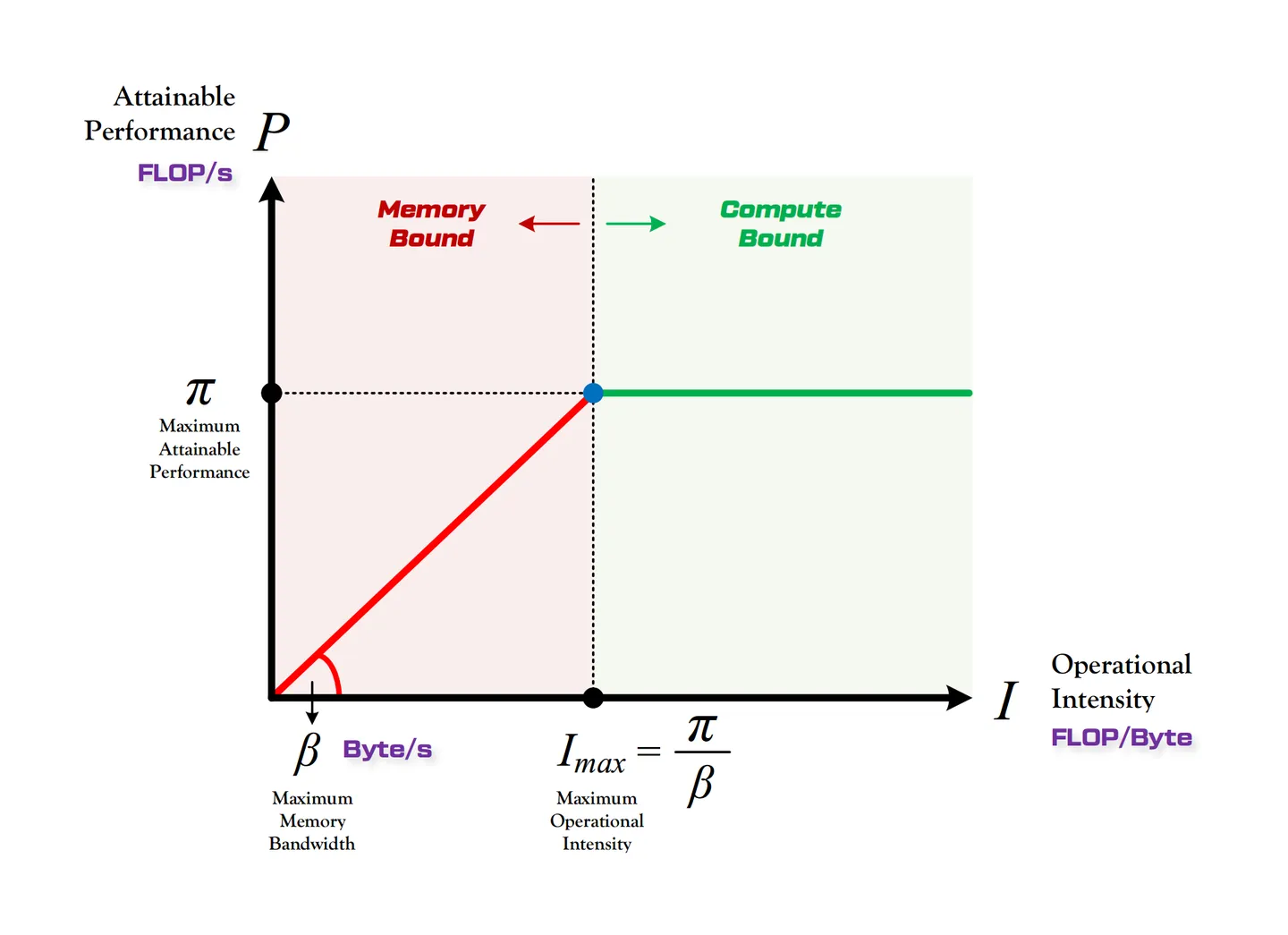
应用:比较 GEMM 和 GEMV
以 GEMM 和 GEMV 为例。假设精度为 FP16,且
X∈R1×n,GEMV:O=XN∈R1×pM∈Rm×n,N∈Rn×p,GEMM:O=MN∈Rm×p我们希望比较以上两个运算。访存包括对于所有输入矩阵和输出矩阵的读写,运算则是矩阵乘法运算,则分别求解两个运算需要访存量 m 和计算量 c
{mGEMVcGEMV=(n+np+p)×2,=2np,{mGEMMcGEMM=(mn+np+mp)×2,=2mnp因此我们可以得到:
⎩⎨⎧IGEMVIGEMM=n+np+pnp=1+(p1+n1)1≈1=mn+np+mpmnp假设 (m,n,p) 都是同数量级,特别的 m=n=p=d,则 iGEMM=3d,因此 IGEMM∝d.
以 H100 为例,其 FP 16 Tensor Core 算力为 π≈1,979 TFLOPS(≈2×1015),内存带宽为 β≈3.35∼3.9 TB/s
因此
Imax=3.35×10122×1015≈600FLOPs/Byte易得 IGEMV≪Imax,且当 GEMM 维度比较小的时候是 memory-bound. 当矩阵比较大的时候是 compute-bound.
参考资料